数据库概念
在一个PostgreSQL数据库系统中,数据的组织结构可以分为以下3 层。
数据库:一个PostgreSQL数据库服务可以管理多个数据库,当应 用连接到一个数据库时,一般只能访问这个数据库中的数据,而不能访问其他数据库中的内容(可以采用 FDW 插件,后面我们会细说)。
在PostgreSQL中,一个数据库服务(或叫实例)下可以有多个数据库,但一个数据库不能属于多个实例,这与Oracle数据库不同。
在Oracle数据库中,一个实例只能有一个数据库,但一个数据库可以在多个实例中(如RAC)
表、索引:一个数据库中有很多表、索引。一般来说,在 PostgreSQL中表的术语为“Relation”,而在其他数据库中则叫“Table”。
数据行:每张表中都有很多行数据。在PostgreSQL中行的术语一 般为“Tuple”,而在其他数据库中则叫“Row”。
模式
什么是模式
在 postgreSQL 中,模式(Schema)是用于逻辑组织数据库对象的一种机制。它可以理解为数据库中的文件夹,用于将不同的对象分组管理。为什么需要模式呢,主要原因有以下几个:
允许多个用户使用同一个数据库且用户直接不会相互干扰。
把数据库对象放在不同的模式下组成逻辑组,使数据库对象便于管理。
第三方的应用可以放在不同的模式中,这样就不会和其他对象的名字产生冲突了。
可以给某个用户或角色授予对特定模式的访问权限,而无需对每个对象单独设置权限。
数据库 > 模式(Schema) > 对象(表、视图、函数等)。模式属于数据库,而数据库对象(如表)属于模式。
实际上,postgreSQL 的 Schema 跟 Oracle 的 Schema 和 MySQL 的 Database 概念比较相识。这里就不细述了,有兴趣的读者可以自行查询。
当我们创建一张表没有指定模式的话,默认会将数据库对象存储在 public 模式中。select 查询的时候也是默认加上了 public,不用手工写上,当然了加上也不会有什么问题。
postgres=# select * from t;
t1
----
t
t
f
(3 rows)
postgres=# select * from public.t;
t1
----
t
t
f
(3 rows)模式搜索路径
在实践中,您会不带模式名称引用一个表,例如staff表,而不是完全限定的名称(例如sales.staff表)。
当我们仅使用表名称引用表时,PostgreSQL 将使用模式搜索路径(即要查找的模式列表)来搜索该表。
PostgreSQL 将访问模式搜索路径中的第一个匹配表。如果没有匹配,它将返回错误,即使该名称存在于数据库中的另一个模式中。
搜索路径中的第一个模式称为当前模式。请注意,当您创建新对象而未显式指定模式名称时,PostgreSQL 还会对新对象使用当前模式。
current_schema()函数返回当前模式:
SELECT current_schema();
current_schema
----------------
public
(1 row)要查看当前搜索路径,可以使用 psql 工具中的 show 命令:
SHOW search_path;、
search_path
-----------------
"$user", public
(1 row)在此输出中:
"$user"指定 PostgreSQL 将用于搜索对象的第一个模式,该模式与当前用户同名。例如,如果您使用postgres用户登录并访问staff表,PostgreSQL 将在postgres模式中搜索staff表。如果找不到任何类似的对象,它将继续在public模式中查找该对象。
第二个元素指的是我们之前看到的public模式。要创建一个新模式,请使用CREATE SCHEMA语句,如下:
CREATE SCHEMA sales;
要将新模式添加到搜索路径,请使用以下命令:
SET search_path TO sales, public;
如果该数据库下有多个模式,我们创建表的时候不指定模式,那么 postgresql 会按照search_path 参数定义的顺序查找模式。我们接下来做个实验看看:
CREATE SCHEMA test1;
CREATE SCHEMA test2;
SET search_path TO test3,test1, test2,public;
#创建一张表不指定模式,那么会放在test1, test2还是public呢,test3是不存在,我们试试看会不会报错
CREATE TABLE staff(
staff_id SERIAL PRIMARY KEY,
first_name VARCHAR(45) NOT NULL,
last_name VARCHAR(45) NOT NULL,
email VARCHAR(100) NOT NULL UNIQUE
);不出我们意料,staff 被放在 test1 里,因为 test1 是已创建模式的第一位。
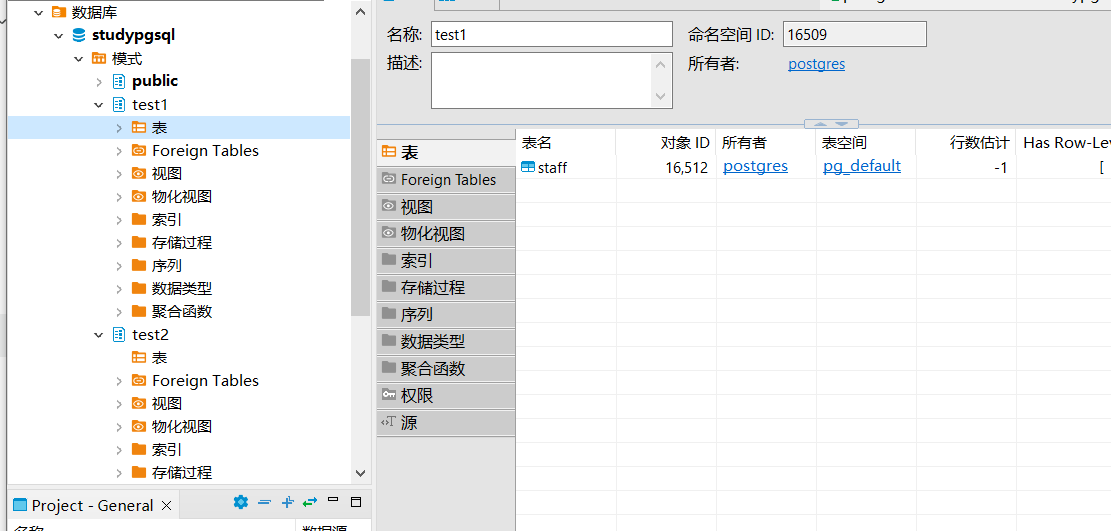
模式的更改和删除
#模式重命名,旧名称下的数据库对象也会移动到新名称下
ALTER SCHEMA schema_name RENAME TO new_name;
#删除模式
DROP SCHEMA [IF EXISTS] schema_name [ CASCADE | RESTRICT ];在删除语法中
RESTRICT 是默认选项,如果该模式下有数据库对象(表,视图,函数等),那么它会拒绝删除。
CASCADE 是级联删除,会删除模式和该模式下所有的数据库对象。
studypgsql=# drop schema newtest1;
ERROR: cannot drop schema newtest1 because other objects depend on it
DETAIL: table newtest1.staff depends on schema newtest1
HINT: Use DROP ... CASCADE to drop the dependent objects too.
studypgsql=# drop schema newtest1 cascade;
NOTICE: drop cascades to table newtest1.staff
DROP SCHEMA
studypgsql=#表继承
表继承是 postgresql 中特有的,它表示可以从一张表继承另一张表的定义,并根据需要添加更多的列或者约束等。
写法1:INHERITS (父表名);
特点:继承了字段和检查约束和非空约束,不包括唯一性、主键和外键约束,但不继承父表索引
写法2:(like 父表名 including all)INHERITS (父表名);
特点:继承了字段和检查约束和非空约束,不包括唯一性、主键和外键约束,也继承了父表索引
查看表之间的继承关系
SELECT inhrelid::regclass AS child_table,
inhparent::regclass AS parent_table
FROM pg_inherits;假如有一张 persons 表:
create table persons (name text,age int,sex boolean);
现在需要再加一张 students 表,students 表比 person 多了一个 class_no 字段:
create table students (class_no int) inherits (persons);
此时往学生表插入三条数据:
insert into students values ('刘备',72,true,112);
insert into students values ('张飞',43,true,112);
insert into students values ('关羽',32,true,112);
此时查询 persons 和 students 表,发现都插入了数据。
postgres=# select * from persons;
name | age | sex
------+-----+-----
刘备 | 72 | t
张飞 | 43 | t
关羽 | 32 | t
(3 rows)
postgres=# select * from students;
name | age | sex | class_no
------+-----+-----+----------
刘备 | 72 | t | 112
张飞 | 43 | t | 112
关羽 | 32 | t | 112
(3 rows)
如果只想让 persons 本身的数据查出来,只需要在查询的表名面前加 only 关键字,示例如下:
select * from only persons;
表空间的概念
PostgreSQL中的表空间允许在文件系统中定义用来存放表示数据库对象的文件的位置。在PostgreSQL中表空间实际上就是给表指定一个存储目录。
表空间旨在允许 PostgreSQL 集群分布到多个存储设备上。创建表空间时,会在集群数据目录的 pg_tblspc 目录中,创建一个指向新创建的表空间目录的符号链接。
使用表空间会使数据库管理更加复杂,因为数据目录不再包含所有数据。
在绝大多数情况下,您不应该在 PostgreSQL 中创建额外的表空间。特别是在与数据目录相同的文件系统上,或与另一个表空间相同的文件系统上,创建表空间是没有意义的。
但是某些场景下使用表空间也有一些好处,比方说:
高吞吐量IOPS,把索引和表放在固态硬盘上。
存储配额,现在数据库或表设置大小限制。
数据库增长,当遇到无法扩容数据库所在的文件系统,可以先移动到其他挂载的文件系统上等等。
在 postgresql 集群中,一个表空间可以让多个数据库使用,而一个数据库可以使用多个表空间。属于多对多的关系。
在 oracle 数据库中,一个表空间只属于一个数据库使用,而一个数据库可以拥有多个表空间,属于一对多的关系。
在 MySQL 中,实际上并没有表空间这个概念,因为每张表都是独立存在的,可以理解成表就是表空间了。
PostgreSQL 表空间简介
表空间是磁盘上的一个位置,PostgreSQL 在其中存储包含数据库对象(例如索引和表)的数据文件。
PostgreSQL 使用表空间将逻辑名称映射到磁盘上的物理位置。
PostgreSQL 有两个默认表空间:
pg_default 表空间存储用户数据。
pg_global表空间存储全局数据。
表空间允许您控制 PostgreSQL 的磁盘布局。使用表空间有两个主要优点:
首先,如果实例初始化时的分区空间不足,您可以在不同的分区上创建一个新表空间并使用它,直到重新配置系统。
其次,可以使用统计数据来优化数据库性能。例如,您可以将频繁访问的索引或表放置在性能非常快的设备(例如固态设备)上,并将包含很少使用的存档数据的表放置在速度较慢的设备上。
创建表空间
要创建新表空间,请使用CREATE TABLESPACE语句,如下:
CREATE TABLESPACE tablespace_name [OWNER user_name] LOCATION directory_path;
表空间的名称不应以pg_开头,因为这些名称是为系统表空间保留的。
默认情况下,执行CREATE TABLESPACE命令的用户是该表空间的所有者。要将另一个用户指定为表空间的所有者,请在 OWNER 关键字后指定它。
directory_path是用于表空间的一个空目录的绝对路径。PostgreSQL 系统用户必须拥有此目录才能在其中读取和写入数据。
表空间创建完成后,可以在CREATE DATABASE、CREATE TABLE、CREATE INDEX语句中指定存储对象数据文件的表空间。
以下语句使用CREATE TABLESPACE创建一个名为ts_primary的新表空间,其物理位置为根目录的/testspace。
CREATE TABLESPACE ts_primary LOCATION '/testspace';
请注意,该目录必须存在,并且postgres要有访问该目录的权限。
要列出当前 PostgreSQL 数据库服务器中的所有表空间,请使用以下\db命令:
postgres=# \db
List of tablespaces
Name | Owner | Location
------------+----------+------------
pg_default | postgres |
pg_global | postgres |
ts_primary | postgres | /testspace
(3 rows)\db+命令显示更多信息,例如大小和访问权限:
postgres=# \db+
List of tablespaces
Name | Owner | Location | Access privileges | Options | Size | Description
------------+----------+------------+-------------------+---------+---------+-------------
pg_default | postgres | | | | 1705 MB |
pg_global | postgres | | | | 565 kB |
ts_primary | postgres | /testspace | | | 0 bytes |
(3 rows)如果要在使用该表空间,需要创建数据库的时候指定该表空间:
CREATE DATABASE logistics TABLESPACE ts_primary;
移动表空间
如果我们需要把表空间移动到别的目录下,该怎么做呢?上文我们说到,会在数据目录下的 pg_tblspc 创建一个指向该表空间的软连接,那么就很简单了,我们 mv 之后,再修改该软连接的指向就行了。下面我们来实操一下。

#停服务
$ pg_ctl stop
#移动表空间
$ mv /testspace/* /newtabspace/
cd /data/pgsql/data/pg_tblspc
$ ls -l
lrwxrwxrwx. 1 postgres postgres 10 May 16 21:35 16540 -> /testspace
#修改软连接
$ ln -fs /newtabspace/ 16540
$ ls -l
lrwxrwxrwx. 1 postgres postgres 13 May 16 21:52 16540 -> /newtabspace/
$ pg_ctl start
#登录客户端验证一下
postgres=# SELECT pg_tablespace_location(16540);
pg_tablespace_location
------------------------
/newtabspace/删除表空间
DROP TABLESPACE语句从当前数据库中删除表空间:
DROP TABLESPACE [IF EXISTS] tablespace_name;
只有表空间所有者或超级用户才能执行删除表空间的DROP TABLESPACE语句。
当删除表空间的时候,要确保该表空间没有数据库才可以删除,不然会报错。如果存在数据库的话,那么就有两种做法:
直接简单粗暴删数据:drop database xxx,同时做好跑路的准备。
把该数据库移动到另一个表空间下:alter database xxx set tablespace = xxxx
postgres=# CREATE DATABASE logistics TABLESPACE ts_primary;
CREATE DATABASE
postgres=# drop tablespace ts_primary;
2025-05-16 22:13:57.658 CST [16750] ERROR: tablespace "ts_primary" is not empty
2025-05-16 22:13:57.658 CST [16750] STATEMENT: drop tablespace ts_primary;
ERROR: tablespace "ts_primary" is not empty
临时表空间
创建临时表空间的流程和普通表空间没有什么不同,实际上他们是一样的。只不过目录最好就选 linux 的临时目录/tmp 和 /var/tmp
当我们创建好临时表空间后,就可以配置该临时表空间为临时对象的默认表空间。这样子创建临时表就会自动创建在该表空间下。
下面我们做实验来实践一下:
[root@192 tmp]# mkdir /var/tmp/tbstmp
[root@192 tmp]# chown postgres:postgres /var/tmp/tbstmp
psql -U postgres
postgres=# create tablespace tbstmp location '/var/tmp/tbstmp';
CREATE TABLESPACE
postgres=# alter system set temp_tablespaces = 'tbstmp';
ALTER SYSTEM
postgres=# select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
postgres=# show temp_tablespaces;
temp_tablespaces
------------------
tbstmp
(1 row)
postgres=# \db+
List of tablespaces
Name | Owner | Location | Access privileges | Options | Size | D
escription
------------+----------+-----------------+-------------------+---------+---------+--
-----------
pg_default | postgres | | | | 1705 MB |
pg_global | postgres | | | | 565 kB |
tbstmp | postgres | /var/tmp/tbstmp | | | 0 bytes |
ts_primary | postgres | /newtabspace/ | | | 7401 kB |
(4 rows)
postgres=# create temporary table tmptable (a int, b char(5));
CREATE TABLE
postgres=# \db+
List of tablespaces
Name | Owner | Location | Access privileges | Options | Size |
Description
------------+----------+-----------------+-------------------+---------+----------+-
------------
pg_default | postgres | | | | 1705 MB |
pg_global | postgres | | | | 565 kB |
tbstmp | postgres | /var/tmp/tbstmp | | | 22 bytes |
ts_primary | postgres | /newtabspace/ | | | 7401 kB |
(4 rows)
我们可以看到,当创建完临时表之后,临时表空间就有数据了,说明该临时表在该临时表空间下。
评论