本章我打算分为三篇来讲解初始化目录下的文件,有些文件我们简单了解就行了,不然一下子上难度很难吃得消。我们主要讲解数据文件,日志文件,参数文件这三个部分就行了。
PostgreSQL 实例数据目录如下:(该版本为PostgreSQL 17.1。各版本并不完全相同。)
PG_VERSION:包含了 PostgreSQL 主要版本号的文件
base:包含了每个数据库的数据文件,表和索引存放在该目录下
current_logfiles:记录日志收集器当前写入的日志文件的文件
global:包含整个数据库集群相关的系统表和数据。
log:存放数据库运行日志。默认是不写入。
pg_commit_ts:存储事务提交时间戳数据,主要用于跟踪事务提交时间。默认是关闭的,由track_commit_timestamp 决定是否开启。
pg_dynshmem:用于存储 动态共享内存段(Dynamic Shared Memory Segments)相关的文件。
pg_logical:用于存储与 逻辑复制(Logical Replication) 和 逻辑解码(Logical Decoding) 相关的数据文件。
pg_multixact:用于存储多事务相关的数据文件。
pg_hotify:用于 LISTEN/NOTIFY 异步消息通知系统,存储待处理的通知消息。
pg_replslot:存储逻辑复制槽(Replication Slots) 的持久化数据,确保 WAL 日志不会被过早删除,直到所有订阅者确认接收。每个复制槽对应一个子目录。
pg_serial:管理可序列化事务(SERIALIZABLE隔离级别) 的状态信息,用于检测并发事务间的冲突。
pg_snapshots:存储事务快照(Transaction Snapshots) 的临时数据,主要用于导出快照以实现并行事务的一致性视图。
pg_stat:持久化统计信息的存储位置(如 pg_stat_* 系统视图的数据)。
pg_stat_tmp:存储统计信息的临时文件,包括动态性能视图(如 pg_stat_activity)的运行时数据。重启后会清空。
pg_subtrans:记录子事务(Subtransactions) 的元数据,用于实现 SAVEPOINT 和嵌套事务。子事务ID与父事务的映射关系存储在此。
pg_tblsps:包含表空间(Tablespaces) 的符号链接。每个子目录是一个软链接,指向自定义表空间的物理路径。在第三章我们有讲到这一点
pg_twophase:存储两阶段提交(2PC) 的事务状态文件。
pg_wal:(旧版本为 pg_xlog)存储预写式日志(WAL) 文件,是崩溃恢复和复制的核心。包含所有数据变更的二进制日志(类似其他数据库的 redo log)。
pg_xat:(旧版本为 pg_clog)记录事务提交状态(XID 状态),存储每个事务是否已提交、中止或进行中。对 MVCC 机制至关重要。
以 conf 结尾的则是相关的配置文件
加粗的配置项是我们本章节要重点说的。其他的我们先有个大概影响就行了。
数据文件
我们平时只按部就班地执行建库,建表,然后插入数据,就可以如愿以偿地实现将我们的数据持久化postgresql 数据库中。
那我们有没有想过一个问题呢?数据存放在哪?如果是学过 MySQL 的就知道,库名是数据目录下的一个文件夹,表名则放在该文件夹下。oracle 则是以数据文件的方式存放,该数据文件最大默认为 32G。
本章主要解决几个疑问,这些数据最终落盘在磁盘的那个位置上?又是以什么样的形式存储?存储的格式又是什么?
PostgreSQL 中的每个表(table)都是由一个或多个堆文件表示。默认情况下,堆文件存放 1 GB 的数据量,当表文件已经达到 1 GB 之后,用户再次插入数据的时候,postgresql 会自动重新创建一个新的堆文件出来,新文件的命名为表 Oid+"."+序号 id(序号 id 从 1 开始依次递增)。
在 PostgreSQL 中,数据库名和表文件名都是使用 Oid 来进行命名。该 Oid 是一个无符号整数。
当我们将数据存储在 PostgreSQL 中时,PostgreSQL 会将用户插入的数据依次存储于文件的常规文件中。对于这样的文件,我们称之为“堆文件(Heap File)”。在PostgreSQL 中,可以将堆文件分为四种类型:
普通堆文件(Ordinary Cataloged Heap):最常见的堆文件类型,用于存储用户数据和系统数据。
临时堆文件(Temporary Heap File):用于存储临时数据,这些数据在会话结束后或重启数据库之后会被删除。
序列堆文件(Sequence File):用于存储序列对象的数据,用于生成唯一的数字序列,常用于主键生成。
TOAST 表堆文件(TOAST File):用于存储超长字段的数据。
在研究数据文件之前,我们需要先知道该文件存放在那个目录下,上文说过,表名是以 Oid 命名,那我们查询出库名和表名的 Oid 是不是就可以知道存放在那个目录下了。比如说我想查询本地 studypgsql 库下的 student 表:
studypgsql=# SELECT oid FROM pg_database WHERE datname = 'studypgsql';
oid
-------
16404
studypgsql=# SELECT oid FROM pg_class WHERE relname = 'student';
oid
-------
24735
#cd到postgresql的数据目录查找
[root@192 data]# find ./ -name 24735
./base/16404/24735有人觉得这样子查找太麻烦了,postgresql 贴心地为我们准备了一个内置函数pg_relation_filepath,该函数只需要传递一个表名既可以快速查找出该表的位置。
studypgsql=# SELECT pg_relation_filepath('student');
pg_relation_filepath
----------------------
base/16404/24735当我们第一次往表中插入数据时,不管该数据多大,postgresql 都会给该文件中分配 8 kb 的空间。
studypgsql=# select pg_relation_size('student');
pg_relation_size
------------------
0
(1 row)
studypgsql=# insert into public.student values (1,'tropix',10);
INSERT 0 1
studypgsql=# select count(1) from student;
count
-------
1
(1 row)
studypgsql=# select pg_relation_size('student');
pg_relation_size
------------------
8192
(1 row)这 8kb 就是我们接下来要说的数据块。
数据块
这数据块的结构如下图所示,相信大部分人第一眼是看不太懂(对比于 mysql,这可简单多了),没事,我们来逐步解析
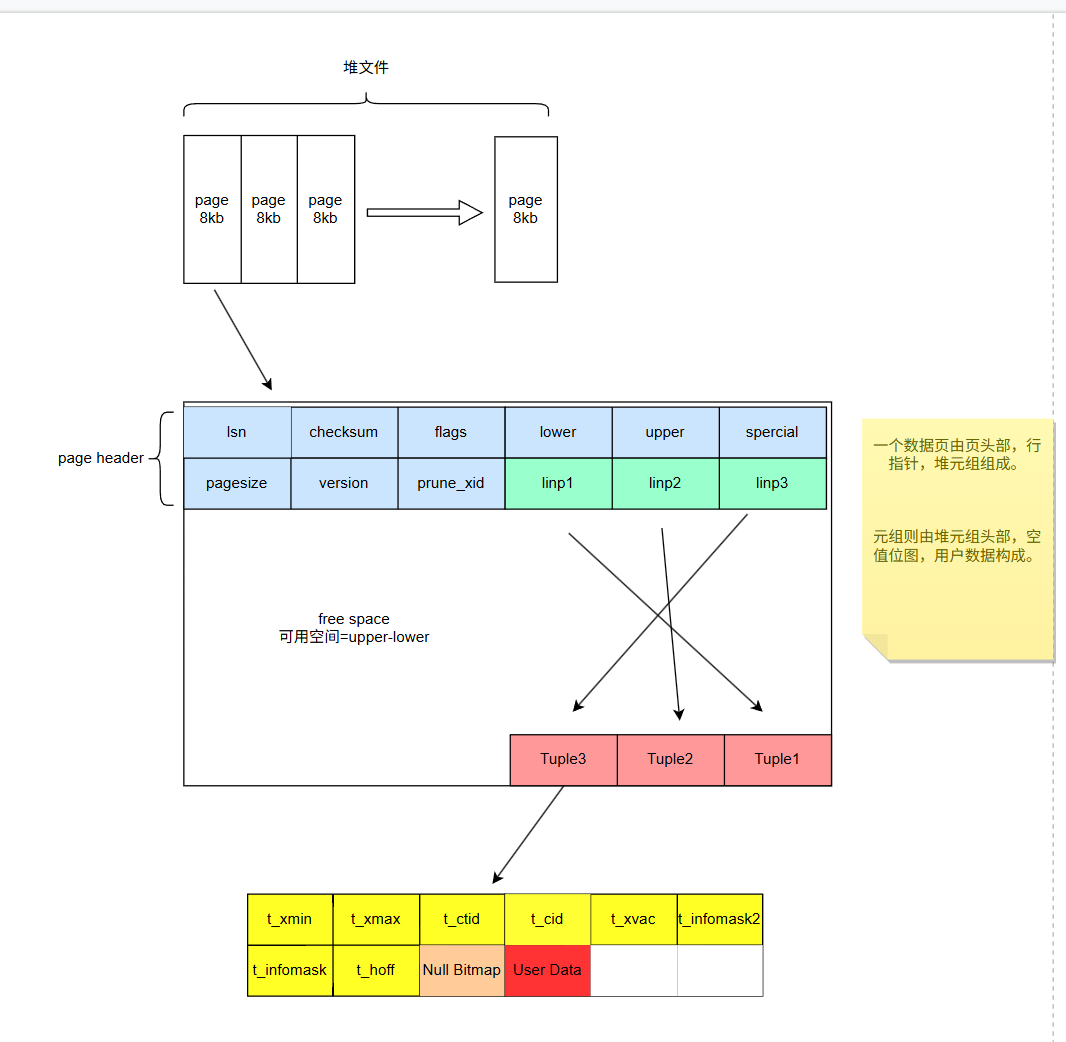
数据块的大小默认是8KB,最大是32KB,一个数据块中存储了多行的数据。
块中的结构是先有一个块头,后面记录了块中各个数据行的指针,行指针是向后顺序排列的,而实际的数据行内容是从块尾向前反向排列的。为什么这样子设计呢?主要基于以下考虑:
当插入数据的时候,数据行从块尾部向前填充,与行指针数组向后扩展形成双向生长,最大限度利用空闲空间。
更新操作时,新 Tuple 可直接插入块尾的空闲区域,旧版本保留用于 MVCC,直接被 VACUUM 清理。
HeapTupleHeaderData内部结构解密
我们看图可知,除了存放数据之外,还有一些额外信息,这部分信息是干嘛用的,接下来我们来仔细讲解下:
t_xmin:存储的是产生这个元组的事务ID,可能是insert或者update语句
t_xmax:存储的是删除或者锁定这个元组的事务ID
t_cid :包含cmin和cmax两个字段,分别存储创建这个元组的Command ID和删除这个元组的Command ID
t_xvac:存储的是VACUUM FULL 命令的事务ID
t_ctid用于记录当前元组或者新元组的物理位置,块号和块内偏移量,例如(0,1)第一个块内的第一个linp,若tuple被跟新,那么就记录新版本的物理位置,跟 oracle 的 rowid 类型类似。
t_infomask2使用其低11位标识当前tuple的attribute的个数,其他位用于HOT以及tuple可见性的标志位
t_infomask用于标识tuple当前的状态,比如是否有OID,是否空的字段,t_infomask每一位代表一种状态,总共16种。
VM 文件和 FSM 文件
在PostgreSQL中更新、删除行后,数据行并不会马上从数据块中被 清理掉,而是需要等VACUUM时清理。为了能加快VACUUM清理的速
度并降低对系统I/O性能的影响,PostgreSQL在8.4.1版本之后为每个数 据文件加了一个后缀为“_vm”的文件,此文件被称为可见性映射表文 件,简称VM文件。VM文件中为每个数据块存储了一个标志位,用来标记数据块中是否存在需要清理的行。
有该文件后,做VACUUM扫描 此文件时,如果发现VM文件中该数据块上的位表示该数据块没有需要清理的行,VACUUM就可以跳过对这个数据块的扫描,从而加快 VACUUM清理的速度。
VACUUM有两种方式,一种被称为“Lazy VACUUM”,另一种被称 为“Full VACUUM”,VM文件仅在Lazy VACUUM中使用,Full VACUUM操作则需要对整个数据文件进行扫描。
参考链接
评论