一、分区的概念
所谓的表分区就是将一张大表,按照分区策略将数据打散到不同的子表中,并通过子表继承父表的方式,物理上将数据文件拆分成多个较小的文件。
分区的好处
对表进行合理的分区可获得更高的可用性,提升 SQL 运行效率(性能)及降低维护成本(可管理性)。
1. 更高的可用性
俗话说的好,不要将鸡蛋都放到一个篮子里,同样的对于数据库而言也是如此,想象一下,一个数百 GB 的表,当某一个数据页面损坏引起整个表不可用时,是多么的悲催。
2. 提升SQL运行效率
对于只查询表中部分数据的场景,好的分区策略,可大幅减少定位数据所需扫描的物理文件数量,从而显著的提升 CURD 的效率。
3. 降低数据维护成本
对于需要定期进行数据归档的表,使用 PostgreSQL 提供的 DETACH 方式,直接解除与父表的继承关系,而无需在原表上进行备份后删除,既能极大的提高工作效率,也能减少对表不必要的操作,从而可降低表的膨胀,同时也以减少 WAL 的量,从而节省不必要资源消耗。
二、什么情况下需要用到表分区
分区虽好,但是要合理使用。
表多大才需要用到表分区呢,这个问题跟那些字段需要建索引一样,是根据业务决定的。在《PostgreSQL 修炼之道》中有提到,当表大小超过数据库的物理内存时就可以用表分区,这个说法不太准确,如果你有几张大表,但这几张表只涉及到单条数据查询且不用频繁删除更新,这时候表分区就没多大意义了。所以表的大小并不能决定是否要分区。
对于经常需要进行数据归档的表,是推荐使用表分区的,一方面可以与生产表快速解绑,与归档表快速挂载,有效地控制膨胀率且不会产生大量 wal 日志。
当业务场景有涉及到时间序列数据查询(比如说交易支付系统查询某个月的交易),大表的范围查询,大表中有明显的分区字段且查询这部分数据(比如说只查询某个省份某个市下的数据)。
三、PostgreSQL 表分区的实现方式
PostgreSQL 中分区分为 2 大类,即继承式及声明式。再 PostgreSQL10.X 之前的版本只能通过表继承的方式实现分区表。
继承式表分区步骤
创建父表,所有的分区都从它继承,父表不存放任何数据。
创建几个子表,每个都是从父表上继承,通常这些表不添加任何字段,与父表保持一致。
给子表添加约束,定义每个分区允许的键值
定义触发器或者规则,把从主表的数据插入重定向到合适的分区表中。
create table test_trigger_part(id serial, flag text, location text, create_time timestamp with time zone); --创建父表
DO $$
DECLARE
base text;
sqlstring text;
i int;
BEGIN
base = 'CREATE TABLE IF NOT EXISTS test_trigger_part_%s (CHECK (create_time >= ''%s'' AND create_time < ''%s'')) INHERITS (test_trigger_part)';
FOR i IN 0..9 LOOP
sqlstring = format(
base,
to_char('2021-05-01'::date + (i || ' day')::interval, 'YYYYMMDD'),
'2021-05-01'::date + (i || ' day')::interval,
'2021-05-01'::date + (i + 1 || ' day')::interval
);
-- 可选:打印 SQL(调试用)
RAISE NOTICE 'Executing: %', sqlstring;
EXECUTE sqlstring;
END LOOP;
END;
$$ LANGUAGE plpgsql;
SELECT tablename
FROM pg_tables
WHERE tablename LIKE 'test_trigger_part_%'
ORDER BY tablename;
#创建触发器函数
CREATE OR REPLACE FUNCTION ins_or_upd_on_test_trigger_part()
RETURNS TRIGGER
AS $$
DECLARE
sqlstring text;
BEGIN
sqlstring = 'INSERT INTO test_trigger_part_%s VALUES ($1.*)';
sqlstring := format(sqlstring, to_char(NEW.create_time, 'YYYYMMDD'));
EXECUTE sqlstring USING NEW;
RETURN NULL;
END
$$ LANGUAGE plpgsql;
#创建触发器
create trigger tg_on_in_or_upd before insert ON test_trigger_part for each row execute function ins_or_upd_on_test_trigger_part (); /*创建触发器*/
#插入数据
insert into test_trigger_part(flag, location, create_time)
select 'flag' || mod(i, 10), md5(i::text), '2021-05-01 00:00:00+08'::timestamptz + (mod(i, 10) || ' day')::interval + (mod(i, 3600) || ' sec')::interval from generate_series(1, 10000) i;声明式表分区
range分区
比较适合用于时间序列数据,年龄分段,价钱区间等。
CREATE TABLE tab_aken (
uid integer NOT NULL,
info_time timestamp NOT NULL,
money decimal(5,2) NOT NULL,
primary key (uid,info_time)
) PARTITION BY RANGE (info_time);
-- 按照月份进行分区
CREATE TABLE aken_2020_1 PARTITION of tab_aken FOR VALUES FROM ('2020-1-01') TO ('2020-1-01'::timestamp + interval '1 month');
CREATE TABLE aken_2020_2 PARTITION of tab_aken FOR VALUES FROM ('2020-2-01') TO ('2020-2-01'::timestamp + interval '1 month');
CREATE TABLE aken_2020_3 PARTITION of tab_aken FOR VALUES FROM ('2020-3-01') TO ('2020-3-01'::timestamp + interval '1 month');
INSERT INTO tab_aken (uid, info_time, money)
SELECT
generate_series(1, 100) as uid,
timestamp '2020-01-01' + (random() * (interval '90 days')) as info_time,
(random() * 1000)::decimal(5,2) as money;list 分区
比较适合离散,有限的分类值,比如说产品类别,区划,国家等。
#列表分区允许为分区指定一个值列表,例如,我们可以将一小部分经常访问的数据存储在热分区中,并将其余的数据移动到冷分区:
CREATE TABLE measurements (
id int8 PRIMARY KEY,
value float8 NOT NULL,
date timestamptz NOT NULL,
hot boolean
) PARTITION BY LIST (hot);
CREATE TABLE measurements_hot PARTITION OF measurements
FOR VALUES IN (TRUE);
CREATE TABLE measurements_cold PARTITION OF measurements
FOR VALUES IN (NULL);
然后,您可以通过更改hot列,在分区之间移动行:
-- Move rows to measurements_hot
UPDATE measurements SET hot = TRUE;
-- Move rows to measurements_cold
UPDATE measurements SET hot = NULL;按 hash 分区
比较适合没有明显分区键,比如说订单 ID,用户 ID 等随机分布的数据。
CREATE TABLE measurements (
id int8 PRIMARY KEY,
value float8 NOT NULL,
date timestamptz NOT NULL
) PARTITION BY HASH (id);
CREATE TABLE measurements_1 PARTITION OF measurements
FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE TABLE measurements_2 PARTITION OF measurements
FOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE measurements_3 PARTITION OF measurements
FOR VALUES WITH (MODULUS 3, REMAINDER 2);三种分区策略的区别
复合分区
如果要构建更复杂的分区布局,那就需要用到复合分区了,也就是多级分区。复合分区并不难,在创建一级分区表的时候指定二级分区策略就行了。下面我们来实践一下,先把一级分区按照年份进行划分,再把二级分区按照月份划分:
CREATE TABLE sales (
id SERIAL,
sale_date DATE NOT NULL,
amount NUMERIC NOT NULL,
region VARCHAR(50)
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2023 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01')
PARTITION BY RANGE (sale_date);
#存储过程
DO $$
DECLARE
year_val TEXT := '2023'; -- 年份参数
parent_table TEXT := 'sales_' || year_val; -- 父表名称(一级分区表)
BEGIN
-- 循环生成1到12月
FOR month_val IN 1..12 LOOP
EXECUTE format(
-- 定义子表名称和日期范围
$SQL$
CREATE TABLE %I PARTITION OF %I
FOR VALUES FROM (%L) TO (%L);
$SQL$,
-- 子表名称格式:sales_YYYY_MM
'sales_' || year_val || '_' || lpad(month_val::TEXT, 2, '0'),
parent_table,
year_val || '-' || lpad(month_val::TEXT, 2, '0') || '-01',
CASE
WHEN month_val = 12 THEN (year_val::INT + 1) || '-01-01' -- 跨年处理
ELSE year_val || '-' || lpad((month_val + 1)::TEXT, 2, '0') || '-01'
END
);
END LOOP;
END $$;
INSERT INTO sales (sale_date, amount, region) VALUES ('2023-05-15', 100.0, 'North');
select * from sales_2023_05;四、利用分区表进行数据维护
删除分区
当要删除大量数据的时候,使用 delete 操作对性能影响较大,不仅会产生大量的wal日志,还可能会导致表膨胀发生。
有了表分区之后,我们直接 drop 对应的子分区即可,不影响全表,对业务透明。
#查询表分区情况
select
c.relname
from
pg_class c
join pg_inherits i on i.inhrelid = c. oid
join pg_class d on d.oid = i.inhparent
where
d.relname = 'parent_table_name';
#删除分区
drop table aken_2020_2;增加分区
增加子分区主要是为了承接超出已有子分区范围的业务新数据入库
CREATE TABLE aken_2020_7 PARTITION of aken FOR VALUES FROM ('2022-6-01') TO ('2020-6-01'::timestamp + interval '1 month');
解绑分区
相对于 drop 子分区,推荐先暂时将子分区从父表中移除的方式,当后续发现还需要子分区的数据,重新将子分区挂载回来即可。和直接 DROP 相比,该方式仅仅是使子表脱离了原有的主表,而存储在子表中的数据仍然可以得到访问,因为此时该子表变成了一个普通的数据表
alter table tab_aken detach partition aken_2020_6;
重新挂载分区
这个就比较有意思了。当你要对数据进行归档时,正常的做法就是先插入到归档表,再从生产表中进行删除。但是有了表分区之后就不用那么麻烦了,直接把这部分数据从生产表解绑,然后再绑定到归档表。
create table test_trigger_partBAK(id serial, flag text, location text, create_time timestamp with time zone) PARTITION BY range(create_time); --创建父表
ALTER TABLE tab_akenbak ATTACH PARTITION aken_2020_1 FOR VALUES FROM ('2020-1-01') TO ('2020-1-01'::timestamp + interval '1 month');
五、PostgreSQL 11 新特性之默认分区
PosgtreSQL 11 支持为分区表创建一个默认(DEFAULT)的分区,用于存储无法匹配其他任何分区的数据。显然,只有 RANGE 分区表和 LIST 分区表需要默认分区。
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
CREATE TABLE measurement_y2018 PARTITION OF measurement
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');以上示例只创建了 2018 年的分区,如果插入 2017 年的数据,系统将会无法找到相应的分区:
INSERT INTO measurement(city_id,logdate,peaktemp,unitsales)
VALUES (1, '2017-10-01', 50, 200);
ERROR: no partition of relation "measurement" found for row
DETAIL: Partition key of the failing row contains (logdate) = (2017-10-01).
使用默认分区可以解决这类问题。创建默认分区时使用 DEFAULT 子句替代 FOR VALUES 子句。
CREATE TABLE measurement_default PARTITION OF measurement DEFAULT;
\d+ measurement
Table "public.measurement"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-----------+---------+-----------+----------+---------+---------+--------------+-------------
city_id | integer | | not null | | plain | |
logdate | date | | not null | | plain | |
peaktemp | integer | | | | plain | |
unitsales | integer | | | | plain | |
Partition key: RANGE (logdate)
Partitions: measurement_y2018 FOR VALUES FROM ('2018-01-01') TO ('2019-01-01'),
measurement_default DEFAULT有了默认分区之后,未定义分区的数据将会插入到默认分区中:
INSERT INTO measurement(city_id,logdate,peaktemp,unitsales)
VALUES (1, '2017-10-01', 50, 200);
INSERT 0 1
select * from measurement_default;
city_id | logdate | peaktemp | unitsales
---------+------------+----------+-----------
1 | 2017-10-01 | 50 | 200
(1 row)默认分区存在以下限制:
一个分区表只能拥有一个 DEFAULT 分区;
对于已经存储在 DEFAULT 分区中的数据,不能再创建相应的分区;参见下文示例;
如果将已有的表挂载为 DEFAULT 分区,将会检查该表中的所有数据;如果在已有的分区中存在相同的数据,将会产生一个错误;
哈希分区表不支持 DEFAULT 分区,实际上也不需要支持。
使用默认分区也可能导致一些不可预见的问题。例如,往 measurement 表中插入一条 2019 年的数据,由于没有创建相应的分区,该记录同样会分配到默认分区:
INSERT INTO measurement(city_id,logdate,peaktemp,unitsales)
VALUES (1, '2019-03-25', 66, 100);
INSERT 0 1
select * from measurement_default;
city_id | logdate | peaktemp | unitsales
---------+------------+----------+-----------
1 | 2017-10-01 | 50 | 200
1 | 2019-03-25 | 66 | 100
(2 rows)此时,如果再创建 2019 年的分区,操作将会失败。因为添加新的分区需要修改默认分区的范围(不再包含 2019 年的数据),但是默认分区中已经存在 2019 年的数据。
CREATE TABLE measurement_y2019 PARTITION OF measurement
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01');
ERROR: updated partition constraint for default partition "measurement_default" would be violated by some row为了解决这个问题,可以先将默认分区从分区表中卸载(DETACH PARTITION),创建新的分区,将默认分区中的相应的数据移动到新的分区,最后重新挂载默认分区。
ALTER TABLE measurement DETACH PARTITION measurement_default;
CREATE TABLE measurement_y2019 PARTITION OF measurement
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01');
INSERT INTO measurement_y2019
SELECT * FROM measurement_default WHERE logdate >= '2019-01-01' AND logdate < '2020-01-01';
INSERT 0 1
DELETE FROM measurement_default WHERE logdate >= '2019-01-01' AND logdate < '2020-01-01';
DELETE 1
ALTER TABLE measurement ATTACH PARTITION measurement_default DEFAULT;
CREATE TABLE measurement_y2020 PARTITION OF measurement
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');
\d+ measurement
Table "public.measurement"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-----------+---------+-----------+----------+---------+---------+--------------+-------------
city_id | integer | | not null | | plain | |
logdate | date | | not null | | plain | |
peaktemp | integer | | | | plain | |
unitsales | integer | | | | plain | |
Partition key: RANGE (logdate)
Partitions: measurement_y2018 FOR VALUES FROM ('2018-01-01') TO ('2019-01-01'),
measurement_y2019 FOR VALUES FROM ('2019-01-01') TO ('2020-01-01'),
measurement_y2020 FOR VALUES FROM ('2020-01-01') TO ('2021-01-01'),
measurement_default DEFAULT六、分区索引
分区索引与索引分区只是调换了位置,但是两个词的含义却是不一样。
分区索引类似于分区表,是基于分区表的基础上把索引分成为更小且更易于管理的部分。全局索引和表是相对独立的,而分区索引自动链接到表的分区。与分区表一样,分区索引提高了可管理性,可用性,性能和可伸缩性。
索引分区是基于普通表,把索引分为更小且更易于管理的部分。表可以是普通表或是分区表。目前 Oracle 支持索引分区,PostgreSQL 不支持。
对于分区表上的索引可以分为两类:本地索引和全局索引。其中全局索引又可以分为分区索引和未分区索引,而本地索引必须为分区索引。因此若某个索引未分区,可以直接断定其为全局索引;若已分区,在根据具体情况进行判断。
本地分区索引:索引的分区方式、分区键和分区数量都与基表完全相同。这里的完全相同指的是
索引的分区键与分区表的分区键完全相同。
索引的分区数量与分区表的分区数量完全相同。
全局索引: 索引的分区结构与基表(分区表)的分区结构完全独立。全局索引可以跨越多个表分区,甚至覆盖整个分区表,适用于特定查询模式的优化。
索引的分区键 可以与基表分区键不同。
索引的分区数量和方式 可以自定义,
如果是按表建索引,又可以分为主表索引和分区表索引。
主表索引:
通过主表创建的的索引,在分区表也会自动创建。
通过主表创建的索引,不能在分区表单独删除,只能在主表上删除。
通过主表创建的索引,在分区表的命名规则是:分区名 索引列名 [ 前两个 include 包含的列名 ]_idx。
分区表索引
在分区表可以独立创建自己的索引,也可以独立删除。
分区表可以当作普通的表来看待创建和管理索引。
七、分区修剪
分区修剪是一种查询优化技术,可以改善声明式分区父表的性能。由参数 enable_partition_pruning 控制。默认是 ON,开启的, 关闭是 OFF。
开启了分区修剪。计划器将检查每个分区的定义并证明不需要扫描该分区,因为该分区不能包含满足查询的 WHERE 子句的任何行。当计划器可以证明这一点时,它将从查询计划中排除(修剪)该分区。
studypgsql=# show enable_partition_pruning;
enable_partition_pruning
--------------------------
off
(1 row)
studypgsql=# explain select * from tab_aken where info_time < '2020-01-29 20:00:00';
QUERY PLAN
----------------------------------------------------------------------------
Seq Scan on aken_2020_01 tab_aken (cost=0.00..66.90 rows=3271 width=18)
Filter: (info_time < '2020-01-29 20:00:00'::timestamp without time zone)
(2 rows)
studypgsql=# set enable_partition_pruning= on;
SET
studypgsql=# explain select * from tab_aken where info_time < '2020-01-29 20:00:00';
QUERY PLAN
----------------------------------------------------------------------------------
Append (cost=0.00..207.79 rows=3273 width=18)
-> Seq Scan on aken_2020_01 tab_aken_1 (cost=0.00..66.90 rows=3271 width=18)
Filter: (info_time < '2020-01-29 20:00:00'::timestamp without time zone)
-> Seq Scan on aken_2020_2 tab_aken_2 (cost=0.00..60.81 rows=1 width=18)
Filter: (info_time < '2020-01-29 20:00:00'::timestamp without time zone)
-> Seq Scan on aken_2020_3 tab_aken_3 (cost=0.00..63.71 rows=1 width=18)
Filter: (info_time < '2020-01-29 20:00:00'::timestamp without time zone)
(7 rows)八、PostgreSQL 各大版本对分区的差异
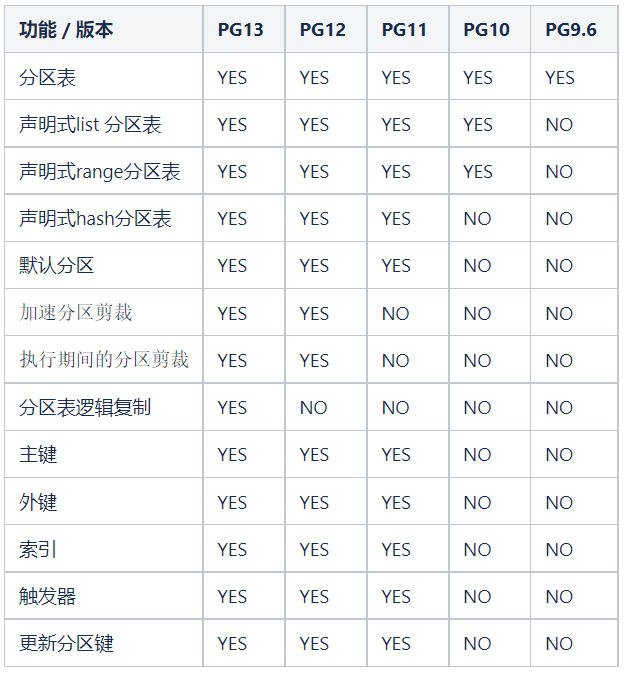
PostgreSQL 在 2005 年的 8.1 版本就支持了分区表,并在 PG10 支持声明式分区表,PG11 分区功能完善,以及 PG12 的快速分区剪裁,性能大幅提升, PG13 分区表支持逻辑复制。
参考文档:
https://www.modb.pro/db/105501
https://www.modb.pro/db/625945
https://www.rockdata.net/zh-cn/tutorial/tune-partition-pruning
评论