一、什么是 autovacuum
简单来说,autovacuum 是 PostgreSQL 中一个自动执行 VACUUM 和 ANALYZE 命令的后台进程。它的主要作用有两个:
回收死元组 (dead tuples) 占用的空间: 当你更新或删除表中的数据时,PostgreSQL 并不会立即物理删除这些数据,而是将它们标记为“死元组”。这些死元组会占用磁盘空间,影响查询性能。autovacuum 会定期运行 VACUUM 命令,回收这些死元组占用的空间,避免表膨胀。
更新表统计信息: PostgreSQL 的查询优化器会根据表的统计信息来选择最优的查询计划。autovacuum 会定期运行 ANALYZE 命令,更新表的统计信息,确保查询优化器能够做出正确的决策。
由两个配置参数决定是否开启:
rack_counts = on # 用于控制数据库活动统计信息的收集
autovacuum = on # 自动清理是否开启
默认是开启的,在生产环境中,我们不应该将其设置为关闭。
二、为什么需要 autovacuum
我们知道 postgresql 在执行 update 和 delete 操作时,原本的数据还是存在表里,时间久了,表就会越来越大,这时候不仅浪费磁盘空间,还会影响执行计划。所以 autovacuum 主要作用有以下几个:
需要 vacuum 来移除死元组
防止死元组膨胀
更新表的统计信息进行分析,以便提供优化器使用
三、什么时候触发autovacuum
autovacuum 并不是无时无刻不在运行的,它会根据一定的条件来触发。这些条件主要由以下几个参数控制:
(一) 触发 vacuum
autovacuum_vacuum_threshold (默认值:50): 触发 VACUUM 的基本阈值。当表的死元组数量超过这个值时,会考虑触发 VACUUM。
autovacuum_vacuum_scale_factor (默认值:0.2): 触发 VACUUM 的比例因子。当表的死元组数量超过 autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * reltuples 时,会触发 VACUUM。其中 reltuples 是表的总行数。
(二) 触发 analyze
autovacuum_analyze_threshold (默认值:50): 触发 ANALYZE 的基本阈值。当表的插入、更新或删除操作数量超过这个值时,会考虑触发 ANALYZE。
autovacuum_analyze_scale_factor (默认值:0.1): 触发 ANALYZE 的比例因子。当表的插入、更新或删除操作数量超过 autovacuum_analyze_threshold + autovacuum_analyze_scale_factor * reltuples 时,会触发 ANALYZE。
举个例子,假设一个表有 10000 行数据,那么:当死元组数量超过 50 + 0.2 10000 = 2050 时,会触发 VACUUM。当插入、更新或删除操作数量超过 50 + 0.1 10000 = 1050 时,会触发 ANALYZE。
以上是比较常见的触发条件,还有以下条件也会进行触发:
指定表上事务的最大年龄配置参数autovacuum_freeze_max_age,默认为2亿,达到这个阀值将触发 autovacuum进程,从而避免 wraparound。
数据库中的活动度和更新频率: autovacuum 会根据数据库中的活动度和表的更新频率动态地触发 VACUUM 操作,以维护表的性能和空间。PostgreSQL-13版本增加的autovacuum_vacuum_insert_threshold 和 autovacuum_vacuum_insert_scale_factor。
autovacuum_naptime参数影响两次系统自动清理操作之间的间隔时间
思考一下
为什么 analyze 触发的条件比 vacuum 要低呢?因为 analyze 要执行的操作比 vacuum 要简单,analyze 只读取数据重新统计信息,而 vacuum 需要更多的 I/O 和 CPU 资源,因为它要修改数据文件。
这样的配置是否合理呢,假设我们现在有两张表,T1 有 100 行数据,T2 有 100 万行。
根据默认参数配置,T1 触发 analyze 和 vacuum 的值是 60 和 70,而 T2 则是 100050 和 200050.
也就是说两张表都做同样数量的 DML 操作,T1 的触发条件是 T2 的 2857 倍!!!!
基于这种情况,我们可以对表单独设置触发条件,这样会忽略全局设置。
alter table orders set (autovacuum_vacuum_threshold = 100);
alter table orders set (autovacuum_vacuum_scale_factor = 0);
四、autovacuum 的执行过程
autovacuum 的执行过程可以分为以下几个步骤:
扫描 pg_class 系统表: autovacuum 会定期扫描 pg_class 系统表,找出需要进行 VACUUM 或 ANALYZE 的表。
判断触发条件: 对于每个表,autovacuum 会根据前面提到的触发条件来判断是否需要执行 VACUUM 或 ANALYZE。
执行 VACUUM 或 ANALYZE: 如果满足触发条件,autovacuum 会启动一个 worker 进程来执行 VACUUM 或 ANALYZE 操作。autovacuum launcher 进程会根据 autovacuum_max_workers 参数来控制并发的 worker 进程数量。
记录日志: autovacuum 会将执行过程中的信息记录到 PostgreSQL 的日志文件中,方便 DBA 进行监控和排查问题
五、autovacuum 相关参数
autovacuum_max_workers 这个配置参数就是来调整每次可以有多少个workers 同时工作,这与你实际当中的表的数量和表的大小有关,对于表比较多并且多是大表的情况下,适当要调整 autovacuum_max_workers 的线程的数量,避免在一个时间周期,部分表无法被轮询到 workers。默认是 3。
autovacuum_naptime:上面说到的定时来进行workers的调用,那么多长时间调用一次,这里的时间是默认是1min ,也就是1分钟调用一次,自动真空来对所有的数据库表进行扫描,这里产生一个问题,如果表的数量过多一次扫描中还未扫描完毕表,但在此的调用已经开始运行了。根据表的数量多少可以调整 autovacuum_naptime的间隔,表的数量太多可以调整的间隔长一些。
log_autovacuum_min_duration:本身并不是一个指导 autovacuum 工作的参数,但他与分析autovacuum 的工作有关,默认值 -1 的意思为不记录所有的autovacuum操作,实际上可以针对超时的vacuum进行记录,如超过1秒的autvacuum操作将被记录 可以将值设置为
log_autovacuum_min_duration= 1000 单位ms
以下参数用于调整 autovacuum 成本计算的参数
vacuum_cost_page_hit:读取已在共享缓冲区中且不需要磁盘读取的页面的开销。 默认值设置为 1。
vacuum_cost_page_miss:提取不在共享缓冲区中的页面的开销。 默认值设置为 10。
vacuum_cost_page_dirty:在某个页面中发现不活动元组时写入该页面的开销。 默认值设置为 20。
autovacuum_vacuum_cost_limit:表示 autovacuum 进程在达到成本限制前可以积累的总成本点数,默认为-1,当为-1的时候,实际上它的值会参考vacuum_cost_limit 的值,而vacuum_cost_limit的值默认为200,所以一般情况下,我们可以把autovacuum_vacuum_cost_limit的值,当成默认为200。
autovacuum_vacuum_cost_delay:当 autovacuum 达到成本限制时,进程应该休眠的时间长度。默认 2毫秒(PostgreSQL 12+版本),早期版本为20毫秒。
突然就冒出这些成本计算参数,一下子让人摸不着头脑,那么这些参数有什么作用呢?
我们来思考一些问题,vacuum 是属于什么类型的操作?一旦达到触发条件,它会先把表的死元组一口气消灭掉还是执行一会休息一会然后再执行一会再休息下,直到完成为止呢?我们带着这几个问题往下学习就知道了。
六、vacuum 的成本计算
vacuum 是一个 IO 密集型操作,我们需要设置一些参数来最小化地限制 vacuum 对 IO 的影响。
也就是说 PostgreSQL 的 vacuum 操作不是一次性全部执行完,而是采用了一种分批次、受控的执行方式。vacuum 会工作一段时间,积累 I/O 成本,达到限制(autovacuum_vacuum_cost_limit)后会休息(autovacuum_vacuum_cost_delay)一会然后再继续执行。如果一次性完成大表的 Vacuum 可能消耗大量 I/O,影响正常业务。
这样说可能还比较抽象,我们来举个例子就知道了。
autovacuum 被触发后,一秒内会读取和写入多少数据量
1 秒=1000 毫秒,休眠时间为 20ms,也就是可以被唤醒 50 次,每次成本限制为 200
如果在共享缓冲区中找到具有不活动元组的所有页面。(在shared_buffers读取速度)vacuum_cost_page_hit 默认为 1。
大约 80 MB/秒 [(200 /vacuum_cost_page_hit) 50 8 KB]
如果从磁盘读取中所有了具有不活动元组的页面。(在os上读取速度)vacuum_cost_page_miss 默认为 10。
大约 8 MB/秒 [(200 /vacuum_cost_page_miss) 50 8 KB]
自动清理的最高写入速度为 4 MB/秒。(vacuum写入速度)vacuum_cost_page_dirty 默认为 20
大约 4 MB/秒 [(200 /vacuum_cost_page_dirty) 50 8 KB]
通常,autovacuum_vacuum_cost_limit 成本平均分配给实例中运行的所有 autovacuum 过程中的autovacuum_max_workers 数。因此,增加autovacuum_max_workers 可能会延迟当前的 autovacuum 执行,
而增加autovacuum_vacuum_cost_limit 可能会导致 IO 瓶颈。
七、实际案例
创建实验用例,直接在表中插入100000 行数据
create table tbl_test (id int, info text, c_time timestamp);
insert into tbl_test select generate_series(1,100000),md5(random()::text),clock_timestamp();分析触发的阈值
analyze:(0.1*100000)+50 =10050
vacuum:(0.2*100000)+50 =20050
更新数据,看下触发情况
update tbl_test set info =md5(random()::text) where id < 10049;
select * from pg_catalog.pg_stat_all_tables where relname='tbl_test';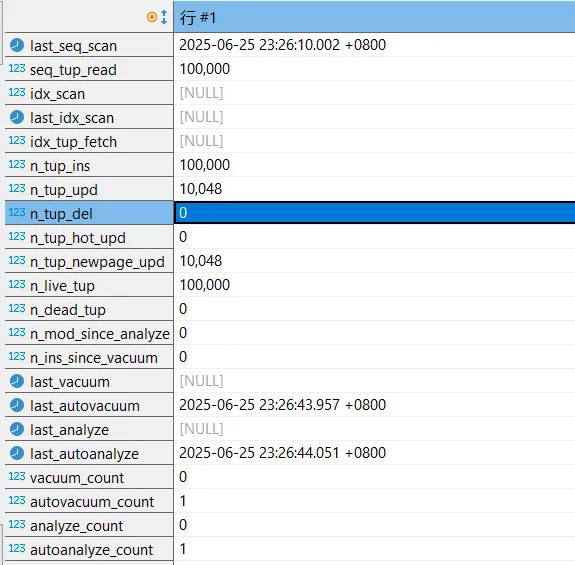
奇怪了,vacuum 达到触发条件,怎么也跟着一块执行了。别急,我们来分析一下。
可能是当 analyze 被触发时,PostgreSQL 会检查表是否需要 vacuum如果表长时间未 vacuum(即使未达到阈值),会"顺便"执行 vacuum。
可能是当 analyze 发现统计信息严重过时可能连带触发 vacuum 以确保统计准确性。
这只是猜测而已,实际原因估计要看看源码才知道了。
参考文档
评论