什么是检查点
检查点是什么呢?我们可以理解为自动保存。举几个日常例子:
当我们用 wps 编辑文档时候,如果这时候停电了,文档没有来得及保存,那之前写的内容就没了,如果这时候文档有自动保存,就可以基于上一次自动保存的位置继续编辑。
当我们玩游戏挑战 boss 的时候,要是挑战之前没有保存,挑战输了就又得从你中途保存的存档继续开始游戏,要是游戏在你挑战 boss 前就帮你自动保存了,那你就不用从中途的存档重新开始游戏,那就省事多了。
基于这两个例子,我们来思考一下几个问题,检查点是怎么被触发的,它是被谁触发的,它的工作原理是什么,怎么调整检查点。
postgresql 会将数据持久化到磁盘里,不过因为磁盘的读写性能比较差,所以又添加了一层缓存。这样每次的数据读写都会优先在缓存中处理,如果数据不存在缓存中,才会从磁盘查找。虽然这样很大的提升了性能,但是缓存不具有磁盘的持久性,在机器断电时就会丢失。
postgresql 为了解决这个问题,结合了磁盘顺序写的特点,引入了 wal 日志机制。当每次数据修改时,还会记录一条日志存储在 wal 文件里,日志包含了此次修改的数据。wal 数据采用添加写的方式,能够充分利用顺序写高效的特点。这样即使数据库意外退出,也能利用 wal 来恢复数据。
当数据库重启时,只需要重放之前所有的wal 日志。不过 wal 日志随着时间的积累会变得非常大,会导致恢复的时间很长。针对这个问题,postgresql 提供了checkpoint 机制,会定期将缓存刷新到磁盘。数据的恢复也只需要从刷新点开始重放 wal 日志,并且之前的 wal 日志就不再有用,可以被回收。
如何触发检查点
postgresql 会创建出一个后台进程,负责处理 checkpoint 。checkpoint 进程会定期检查是否满足时间触发条件:
检查点间隔时间由checkpoint timeout设置(默认间隔为300秒(5分钟))
postgres=# show checkpoint_timeout;
checkpoint_timeout
--------------------
5min
在9.5版或更高版本中,pgxlog中WAL段文件的总大小(在10版或更高版本中为Pg_WAL)已超过参数max_WAL size的值(默认值为1GB(64个16MB文件))。
PostgreSQL服务器在smart或fast模式下关闭。
手动触发:当用户执行checkpoint命令也会触发,这个命令必须由超级用户才能执行。
检查点处理流程
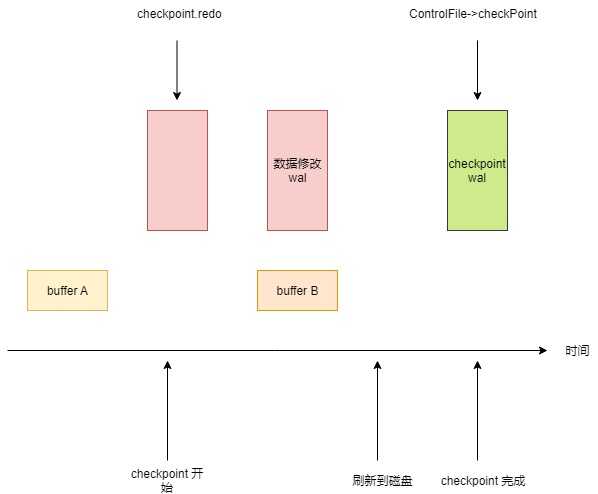
每次 checkpoint 开始时,都会记录当前最新的 wal 日志位置,称作为检查点(redo),等把脏块数据刷入磁盘后,再写入 checkpoint,如下图所示:
为什么要分为 redo 和 checkpoint 呢?因为写入 checkpoint 之前需要把缓存中的脏块刷新到磁盘上,这个过程需要时间,我们可以用pg_controldata 查看 redo 和 checkpoint 的值是不太一样的,只要当前数据库没啥事务再执行的时候,这两个值才有可能是一样的。
当数据库恢复时,会从检查点开始回放 wal 日志。

上图左边的蓝色方块,代表着 checkpoint 开始的 wal 数据。因为 checkpoint 并不会影响用户请求,所以之后的红色方块代表着之后的请求。
postgresql 在修改缓存时,会记录对应的 wal 日志,所以 checkpoint 完成后,这些蓝色的 wal 日志对应的修改,就能确保已经持久化到磁盘了。
checkpoint 完成后,会将检查点的位置记录下来,保存到 checkpoint wal 日志中。为了方便数据库恢复时,快速找到 checkpoint 的数据,会将它的位置存储到 pg_control 文件。
这里额外提一下,会涉及到数据恢复时的概念。假如下面这种情况,当一个 buffer 对应的数据,在checkpoint开始后,刷新到磁盘之前时,用户执行了一条 insert 请求,修改了这个 buffer 的数据。
假设该数据库发生崩溃,在恢复时,从检查点开始。它会首先从磁盘读取数据 data b,然后遇到 insert 语句对应的 wal 日志,它需要知道该 wal 日志对应的修改,已经成功持久化了,不然就会发生恢复错误。
检查点调整
检查点发生的间隔时间决定了实例恢复需要的时长,checkpoint timeout设置的值应该根据业务的需求设置,以实例崩溃时,下一次打开数据库时长的容忍度而设置。
间隔时间短,则实例恢复需要的时间就短,可提高数据库的可用性,但是会增.加IO操作,降低数据库状态性能,检查点发生时属于密集型I/0操作,会占用大量系统资源。
间隔时间长,则实例恢复需要的时间就长,会降低数据库的可用性,但是会减少I/O操作,提高数据库状态性能。
Checkpoint_complete_target 配置项
这里需要详细的介绍checkpoint_complete_target配置项,它在 checkpoint 优化时比较重要,同时也比较复杂。我们知道 checkpoint 执行时会占用系统资源,尤其是磁盘 IO,所以为了减少对系统的影响,会进行 IO 限速。
如果开启了checkpoint_complete_target配置,那么此次 checkpoint 不需要立即完成,它会将完成时间控制在checkpoint_timeout_ms * checkpoint_complete_target。这样磁盘 IO 就可以平缓的运行,将其控制在一定的影响范围之内。
如果 checkpoint 不能立即完成,那么旧有的 wal 日志也就不能立即删除。因为max_wal_size规定了 wal 日志的最大值,那么我们需要将由于 wal 过大而引起 checkpoint 的触发值调低,因为在执行 checkpoint 的时候吗,同时会有新的 wal 日志产生。那么显而易见,到达 wal 日志大小的顶峰是checkpoint 即将完成的时刻,因为这时包含了此次触发的wal 日志,加上新增的 wal 日志。
假设触发值为trigger_wal_size,那么checkpoint_timeout时间内,wal 日志新增的大小最多为trigger_wal_size。我们假设 wal 日志的增长速度是相同的,那么此时增长的 wal 日志大小为trigger_wal_size * checkpoint_completion_target。
为了保证顶峰时刻,wal 日志大小等于max_wal_size,可以计算出触发值
trigger_wal_size + trigger_wal_size * checkpoint_completion_target = max_wal_size;
trigger_wal_size = max_wal_size / (1 + checkpoint_completion_target)
当然为了保证完成的时间在checkpoint_timeout_ms * checkpoint_complete_target,在执行缓存刷新到文件时,需要进行限速。
参考文档:
评论