前言
本专栏分为四大部分:
SQL 语句的执行时间和逻辑读是可以结合原理计算和预估出来的。
极速优化 SQL-在不懂业务的情况下用过技术手段结合原理快速分析和优化 SQL
SQL 效率异常分析-分析为什么 SQL 时快时慢或者为什么没有走预期的执行计划
SQL 改写优化-对常见必须要 SQL 改写的场景进行逐一讲解
本章内容
select * from T10G 访问一张表的全部数据预计需要多少时间?
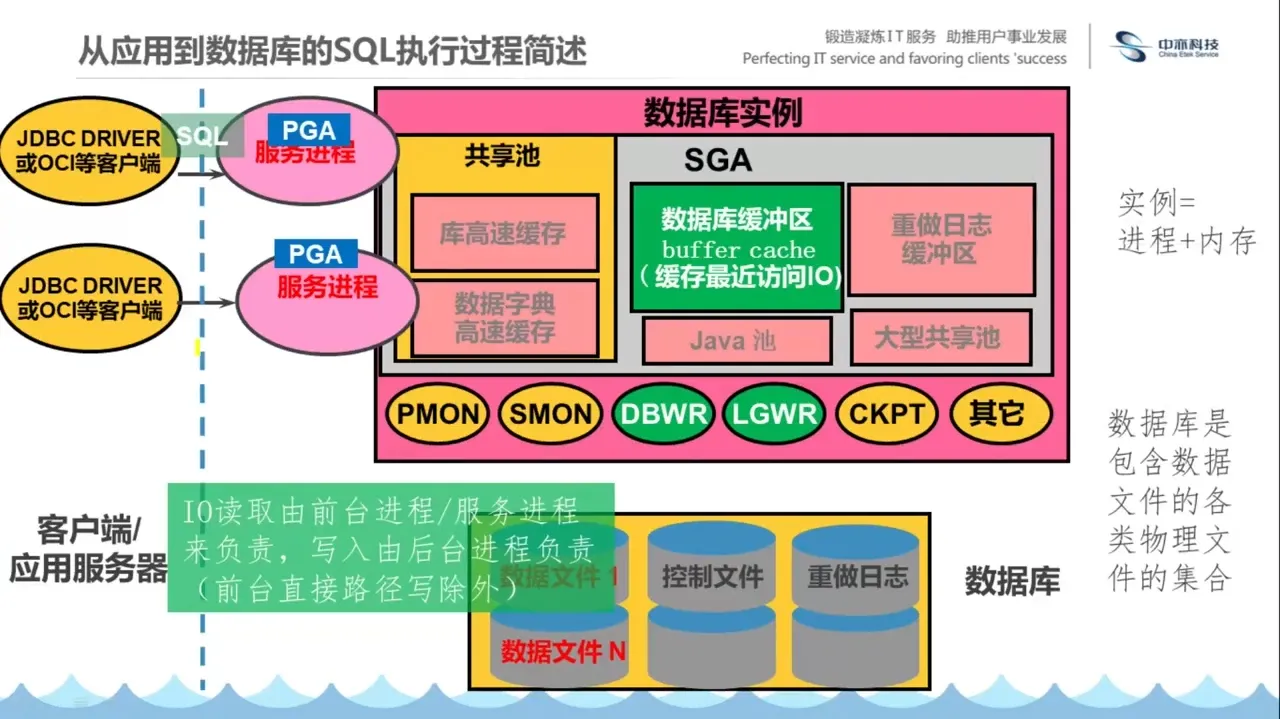
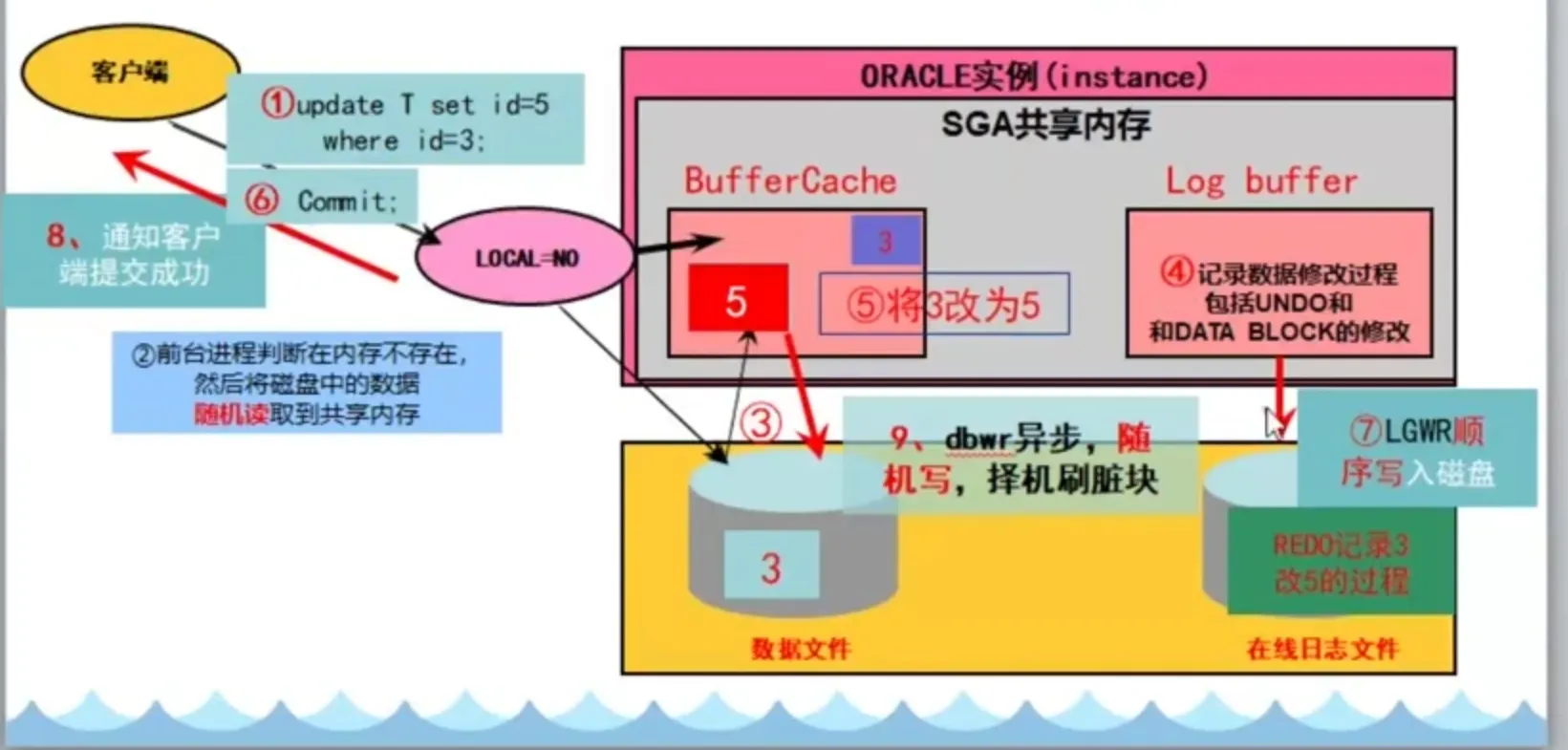
这个 SQL 从应用到了数据库以后,DB 是怎么把用户数据找回并传回的
量化能力初养成-影响估算该 SQL 执行时间的因素
体验量化的魅力!预估访问一张表的 SQL 执行时间的计算公式
表中数据存储简述
一个数据文件被格式化一个一个的 BLOCK,每个 BLOCK 大小是 8K,连续一组的 block 组成一个 extent(区)。
一个数据文件允许存储多张表,所以数据库必须记录表和数据的映射关系。
元数据-段头。数据字典 seg$记录了表的段头块是哪个文件哪个 BLOCK。
元数据-extentMap,段头块中保存了哪些文件哪些 extent 属于该表的映射关系。
元数据-row directory,一个块 8K 并不是全部存储用户数据,块内部的元数据记录了每一张在 8K 内的偏移量。
估算访问 10G 大小的表的执行时间
如果想要正确回答这个问题,需要对硬件和软件有所了解才行。
因为 IO 相对比 CPU,内存要慢很多,因此执行时间以 IO 为准。
而软件方面的因素就比较多了,数据库自身的实现/算法,怎么从硬盘里获取数据等等。
我们知道,所有的数据必须从磁盘读取到数据库共享内存或私有内存进行,不做特殊说明,则读取到共享内存。数据库操作的最小单位为 BLOCK,为了读取一行,也必须读取整个 BLOCK。一个 BLOCK 默认大小是 8192。
数据库一次读取多个块叫做多块读,如果只读取一个块,叫做单块读。那一次 IO 读取多少个 BLOCK 呢,典型地,db_file_multiblock_read_count 从 16 到 128 不等,在不做特殊说明的情况下,本系列多块读以 16 为准。
一次 IO 的耗时是 4ms,后面我们会进行详细说明。
计算公式:
访问表需要发生的 IO 次数*单次 IO 响应时间
=(访问表的大小/单次 IO 读取的大小)* 单次 IO 响应时间
=(访问表的大小/(多块读个数 BLOCK 大小)) 单次 IO 响应时间
= ((10*1024*1024*1024)/(16*8192)) * 4ms
= 327680 ms
= 327 s
所以我们得出结论,一张 10G 的表访问需要 5 分钟。
怎么让表访问更快呢?
排除硬件,就只剩下调整 BLOCK_SIZE 大小,更大的多块读个数可以单次 IO 读取更多的数据,从而访问大表更快。现在新版本的数据库默认将多块读个数自适应到最大 128,默认的 BLOCK_SIZE 是兼顾 IO 效率,并发冲突,热块的综合考量。
一次 IO 4ms 怎么计算来的
如果想要回答好这个问题,那我们要先对硬盘有点了解才行。硬盘的构造如果下图所示

通常情况下,一个盘片由一个或多个组成,这些盘片被固定到一个可以旋转的主轴上。主轴带动盘片以固定的旋转速率进行高速的旋转。
其中盘片的表面被划分了一圈一圈的磁道,每个磁道又被划分了多个扇区,每个扇区可以存储 512 个字节的数据。如下图所示
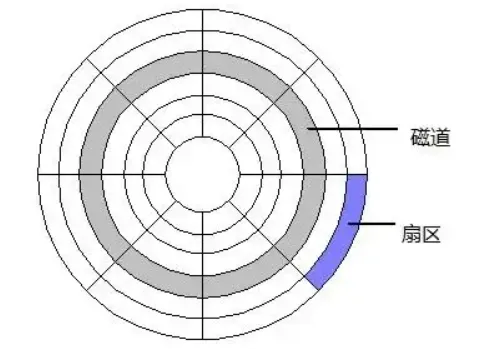
所有的读写头连接到一个传动臂上,通过传动臂在半径方向上的移动,这些读写头可以读取任意磁道上的数据,我们把这种机械运动称之为寻道。
在完成寻道之后。读写头就保持不动了。寻道完成后,如果想要完成对目标扇区的读写操作,还需等待盘片旋转到目标扇区,这一过程称为旋转延迟。
通过盘片旋转(旋转延迟)和磁头感应,定位到目标扇区的过程就称之为寻址。
其中读写头距离盘片表面的高度高约是 0.1 微米,在这样狭小的间隙里,任何微小的灰尘或者剧烈的震动都会可能导致读写头撞向磁盘,从而导致磁盘损坏。
对扇区的访问时间主要由三部分组成,寻道时间,旋转时间以及传送时间。
寻道时间:当目标扇区所处的磁道与当前读写头所在的磁盘不同时,那么传动臂需要将读写头移动道目标扇区所在磁道,传动臂移动所需时间就是寻道时间。寻道时间主要取决于读写头的当前位置和目标位置的距离。通过对随机扇区的访问测试,通常平均寻道时间在 3~9ms 左右。
旋转时间:一旦读写头移动到目标磁道上,接下来,还需要等待目标扇区的第一个数据位旋转到读写头下才能进行读写数据。 这个过程由两个因素决定:一个是当前读写头所在扇区位置与目标扇区的距离,最坏的情况是,读写头刚刚错过了目标扇区,所有必须等待盘片转一圈才能读取数据。另外一个因素是盘片的旋转速度。例如一个盘片的旋转速度是 7200 转,旋转一圈也就是 60s/7200RPM*1000 约等于 8ms,所以在最坏的情况下旋转延迟大约是 8ms。当读写头位与目标扇区时,就可以开始读写数据了。
传送时间:一个扇区的传送时间依赖于旋转速度以及每条磁道的扇区数目。假设每条磁道上的平均扇区数是 400 个,转一圈需要 8ms,所以转过一个扇区大约需要 0.02ms,也就是一个扇区的数据传送需要 0.02ms 就可以完成.
通常普通人选择磁盘只关心磁盘容量大小,也就是能存放多少数据。
对于比较了解电脑的人,则会关心转速,顺序读写和随机读写能力。顺序和随机有什么区别呢?我们来举个例子:
比如说你是一个仓库管理员,现在你需要把一台冰箱搬运出库,虽然很重,但你只需要查找一次。
如果现在是有多个物品需要搬移,比如说:牙刷,纸巾,一本书,一个苹果,一件衣服等等,虽然这些东西很轻,但是你需要先找到这些物品。耗时比一台冰箱可能还要大。
这就是我们对一个大文件进行拷贝的时候比较快,但是对一个目录下有很多小文件拷贝的速度就慢很多了。
我们可以用CrystalDiskMark 进行检测看看,SEQ 就表示顺序读写,RND 表示随机读写。我们可以看到顺序读写能力要远远大于随机读写的。
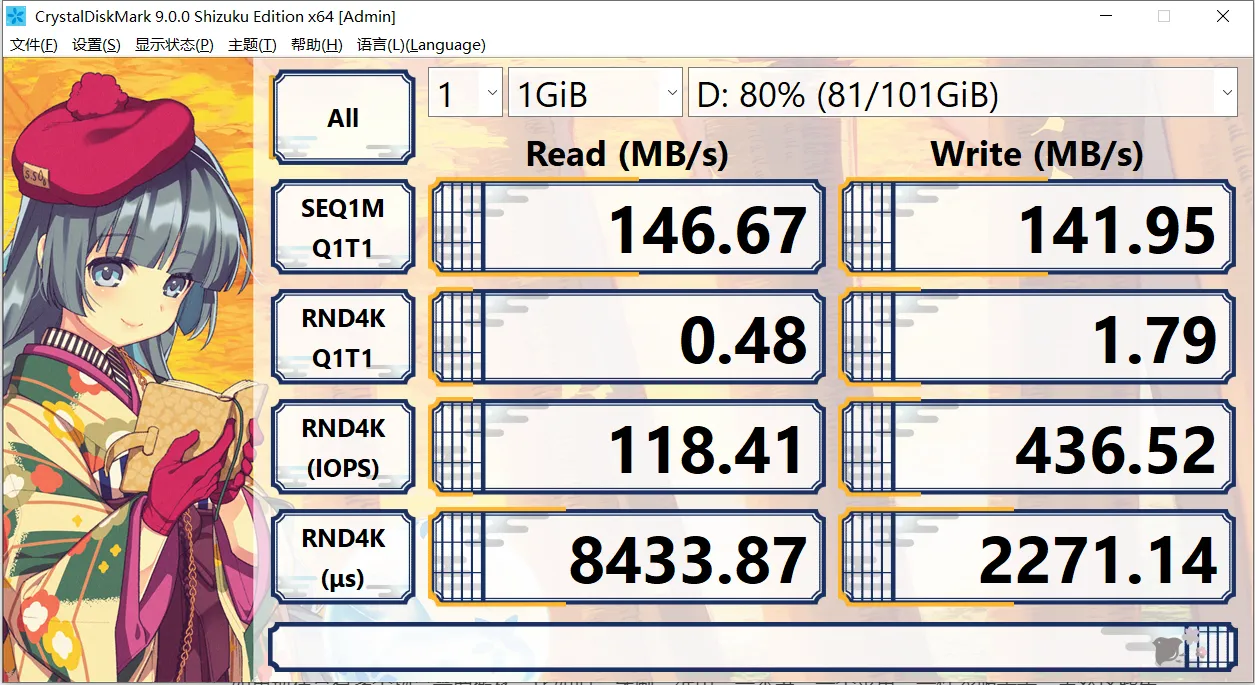
IOPS 表示每次支持 IO 个数的上限。
磁盘吞吐量(Disk Throughput) 是指磁盘在单位时间内能够传输的数据总量,通常用来衡量磁盘的整体数据传输效率,单位一般为 MB/s 或 GB/s。
机械硬盘的吞吐量通常受到 磁盘转速(如 5400 RPM 或 7200 RPM)和 接口类型(如 SATA、SAS 等)限制。常见的数值如下:
7200 RPM 硬盘:吞吐量一般在 100-150 MB/s 之间。高性能的机械硬盘在最理想的条件下可能接近 200 MB/s。
5400 RPM 硬盘:吞吐量通常较低,一般在 50-100 MB/s 之间。
了解完这些知识后,我们就可以推导出一次 IO 的耗时了
一般机房用的硬盘是 15000 转
15000 转/RPM,RPM = Rounds for Minutes
即 60000 /15000 转 等于 4ms,随即 IO,平均需要转一圈的过程获得所需数据。
因此,我们认为 15000 转的硬盘,随机 IO,平均 IO 响应时间为 4ms
IOPS、延迟和吞吐量等存储性能指标
从 IO 响应时间推导 IOPS(每次支持的 IO 个数上限)
既然一个 IO 是 4 毫秒,一秒就是 1000 毫秒。1000ms/4ms =250 个 IO,因此 15000 转的磁盘理论 IOPS 为 250,即每秒支持的 IO 个数为 250 个。
如果是 7200 转,则是一次 IO 则是 8ms,每秒支持的 IO 个数为125 个。
那我们思考几个问题:
SQL 执行过程中会用到什么 IO 类型?
后台进程的 I/O 行为
为什么日志要顺序写?因为顺序写减少磁头移动,最大化磁盘吞吐量,保障事务的高效持久化。
异步刷脏块要用随机写?因为脏块的位置是不连续的,这些块最终要写入数据文件的不同位置(不同数据块、不同数据文件)。
通过表的字段和行数估算表的大小
create table tb0101(id number,name varchar2(20),other_col_char(2000));如果我们执行完这条建表语句,先不插入数据,那么这个空表现在会被分配磁盘空间吗?有些人说会,有些人说不会,那么我们执行下面的语句看看:
select bytes/1024 size_k from dba_segments where segment_name='TB0101';实际上,建表后是否分配空间是由 DEFERRED_SEGMENT_CREATION 这个参数决定的,该参数表示延迟段创建,默认是 TURE,alter system set deferred_segment_creation=FALSE;
我们把参数关闭后再重新创建一张表,会发现这次给分配了 64KB 的空间。
创建表之后在PLSQL 里看到表的定义非常复杂,多了些额外参数。
-- Create table
create table TB0101
(
id NUMBER,
name VARCHAR2(20),
other_col CHAR(2000)
)
tablespace ASSM_TS_NEW
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
这些参数是默认自带的,让我们简单了解下是什么意思
PCTFREE 10 表示数据块保留 10%的空闲空间,这空闲空间用于未来数据更新时,避免行迁移。
INITRANS 1 和 MAXTRANS 255INITRANS 1:每个数据块初始分配的事务槽(Transaction Slot)数量(默认为 1)。事务槽用于支持并发事务修改同一数据块。MAXTRANS 255:每个数据块允许的最大事务槽数量(Oracle 10g+ 已弃用此参数,默认固定为 255)。
STORAGE 子句定义表空间的物理存储分配规则:INITIAL 64K:初始区(Extent)大小为 64KB。NEXT 1M:后续扩展的区大小为 1MB。MINEXTENTS 1:表空间创建时分配的初始区数量(这里是 1 个区)。MAXEXTENTS UNLIMITED:表空间可扩展的最大区数量无限制。
插入记录
begin
for i in 1..1000 loop
insert into tb0101 values (i,i||'_a','other_col...');
end loop;
commit;
end;评估一张表的大小我们首先会想到的是行数*平均行长(字段长度之和),
select avg(length(id)),avg(length(name)),avg(length(other_col)) from tb0101;
|AVG(LENGTH(ID))|AVG(LENGTH(NAME))|AVG(LENGTH(OTHER_COL))|
|---------------|-----------------|----------------------|
|2.893 |4.893 |2,000 |我们直接取整计算一下
(3+5+2000)* 1000 / 1024 约等于 1960.93。不要忘了我们有说过,数据块会保留百分之 10 的空间,那么我们估算的结果就是 1960 除以 0.9 等于 2179.81。那真实情况是不是呢?
SELECT sum(bytes)/1024 AS total_size_kb FROM user_segments WHERE segment_name = 'TB0101';
|TOTAL_SIZE_KB|
|-------------|
|3,072 |翻车了,这和我们估算的差了 1000kb,这是怎么一回事呢?不要着急,让我们接着往下探索。
还记得我们说过的段概念吗?
段很简单,占用空间的对象称为段,表,索引,物化视图都会占空间,我们都可以称之为段。
段肯定是一个对象,但是对象不一定是段,例如视图,存储过程,函数它实际在数据库中保存了一个定义,不像表、索引,随着数据量的增大而增大。
那段往下的单位就是块了吗?那我们思考一个问题,如果有一张 1T 的表,那么它有多少个数据块,1TB / 8KB =134,217,728块,也就是 13 亿!!!Oracle 要记录这 13 亿行的信息,你觉得有可能吗?显然不太可能,这里就引出了区的概念。
区(Extent)是由一组连续的块组成的存储单元,是Oracle分配空间的基本单位。
块是数据存储的最小单元,多个数据块就组成了区,当用户创建了一张表时,实际上就是创建了一个数据段segment,初始化是 8 个数据块,也就是一个区,那么随着数据量不断的插入,每次还只是分配 8 个数据块吗?我们直接查询就知道了。
select t.segment_name,t.EXTENT_ID,t.tablespace_name,t.BYTES/1024,t.BLOCKS from user_extents t where t.segment_name='TB0101';
|SEGMENT_NAME|EXTENT_ID|TABLESPACE_NAME|T.BYTES/1024|BLOCKS|
|------------|---------|---------------|------------|------|
|TB0101 |0 |ASSM_TS_NEW |64 |8 |
|TB0101 |1 |ASSM_TS_NEW |64 |8 |
|TB0101 |2 |ASSM_TS_NEW |64 |8 |
|TB0101 |3 |ASSM_TS_NEW |64 |8 |
|TB0101 |4 |ASSM_TS_NEW |64 |8 |
|TB0101 |5 |ASSM_TS_NEW |64 |8 |
|TB0101 |6 |ASSM_TS_NEW |64 |8 |
|TB0101 |7 |ASSM_TS_NEW |64 |8 |
|TB0101 |8 |ASSM_TS_NEW |64 |8 |
|TB0101 |9 |ASSM_TS_NEW |64 |8 |
|TB0101 |10 |ASSM_TS_NEW |64 |8 |
|TB0101 |11 |ASSM_TS_NEW |64 |8 |
|TB0101 |12 |ASSM_TS_NEW |64 |8 |
|TB0101 |13 |ASSM_TS_NEW |64 |8 |
|TB0101 |14 |ASSM_TS_NEW |64 |8 |
|TB0101 |15 |ASSM_TS_NEW |64 |8 |
|TB0101 |16 |ASSM_TS_NEW |1,024 |128 |
|TB0101 |17 |ASSM_TS_NEW |1,024 |128 |我们可以看到从 第 16 个区开始,Oracle 给一个区分配了 128 个块,大小为 1M。为什么 Oracle 要这样子做呢?我在另一篇文档里有详细介绍,感兴趣的可以移动到该文章进行观看。
到此就真相大白了,oracle 分配了两个区是1M,而我们少计算了一个 1M 的大小。
这说明很多人以前的预估是错误的,我们要深入学习数据的底层存储才行。
相信你看完收获肯定满满,有不懂的地方可以评论区留言,我们一起进步一起学习。
评论