复制是基于 binlog 实现,学习之前必须要先掌握 binlog。MySQL 不是还有 redo 日志吗,为什么不直接基于 redo 日志来实现复杂。
实际上,redo 只有 innodb 引擎所独有的,MySQL 除了 innodb 还有 myisam,csv,memory 等存储引擎,对这些存储引擎的操作同样需要持久化到 binlog 里。换言之,redo log 是在存储引擎层实现的,而 binlog 则是在 Server 层实现的。
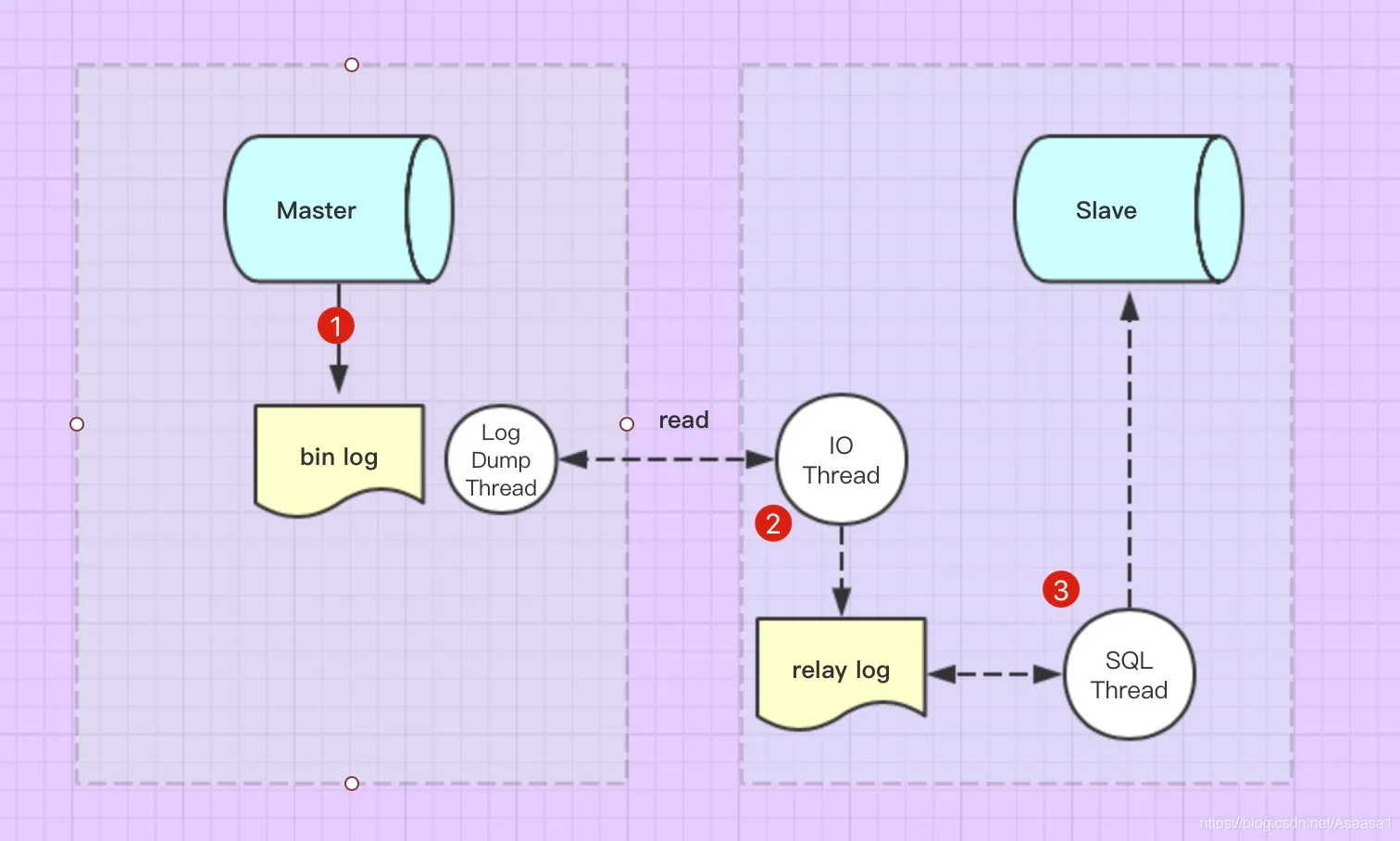
复制涉及到以下三个线程
主库 binlog dump 线程
从库 I/O 线程
从库 SQL线程
复制的大致流程如下:
从库执行完 start slave 命令后,会创建两个线程,I/O 线程和 SQL 线程。
I/O 线程会建立一个到主库的连接,相应地,主库会创建一个 dump 线程来响应这个连接的请求。此时对主库来说,从库的I/O 线程就是个普通的客户端。
I/O 线程首先告诉主库应该从何处开始发送二进制日志事件。
主库的 dump 线程开始从指定位置点读取二进制日志事件,并发送给 I/O 线程。
I/O 线程接收到二进制日志事件后会将其写入 relay log。
SQL 线程读取 relay log 中的二进制日志事件,然后进行重放。
1. 异步复制(Async Replication)
MySQL 默认的复制方式。主库在执行完客户端提交的事务后,会立刻给客户端反馈。主库并不关心从库是否已经接受或应用完该事务。
这会带来一个问题,假如主库出现故障,主库提交的事务可能还没传到从库上,这时把从库提升为主库,就会导致新主库上数据不完整。
2. 同步复制(Sync Replication)
主库执行完事务后,需要等所有从库应用完事务才给客户端反馈。比较耗时,容易引起堵塞,对数据库性能影响较大。
3. 半同步复制(Semi-Sync Replication)
介于异步复制和全同步复制之间。主库在执行完客户端提交的事务后,不会立刻给客户端反馈而是需要等待至少一个从库接收到(注意,只是接收,不是应用)该事务对应的二进制日志事件。
相对于异步复制,半同步复制无疑提高了数据的安全性,同时相对于全同步复制,它对数据库的性能影响也没有那么大。
MySQL 5.5版本之后引入了半同步复制功能,主从服务器必须安装半同步复制插件,才能开启该复制功能。
如果等待超时,超过rpl_semi_sync_master_timeout参数设置时间(默认值为10000,表示10秒),则关闭半同步复制,并自动转换为异步复制模式。当master dump线程发送完一个事务的所有事件之后,如果在rpl_semi_sync_master_timeout内,收到了从库的响应,则主从又重新恢复为半同步复制。
rpl_semi_rsync_master_wait_point=after_commit
4. 增强半同步复制(lossless Semi-Sync Replication,无损复制)
增强半同步是在MySQL 5.7引入,其实半同步可以看成是一个过渡功能,因为默认的配置就是增强半同步,所以,大家一般说的半同步复制其实就是增强的半同步复制,也就是无损复制。
增强半同步和半同步不同的是,等待ACK时间不同 rpl_semi_sync_master_wait_point = AFTER_SYNC(默认) 半同步的问题是因为等待ACK的点是Commit之后,此时Master已经完成数据变更,用户已经可以看到最新数据,当Binlog还未同步到Slave时,发生主从切换,那么此时从库是没有这个最新数据的,用户看到的是老数据。 增强半同步将等待ACK的点放在提交Commit之前,此时数据还未被提交,外界看不到数据变更,此时如果发送主从切换,新库依然还是老数据,不存在数据不一致的问题。
这张图很好地解释了这几种复制模式的区别
5. 延迟复制
延迟复制是 MySQL5.6 推出的,它的核心思想是一个事务执行后,会等待若干秒才会在从库执行。
延迟复制个人感觉比较鸡肋,只针对某些情况下比较好用,比如误删了历史数据或者不怎么频繁更新的数据。
如果是误删了一张频繁更新的业务表,要是去从库去找回误删的数据,这时肯定是缺数据的。
开启延迟复制较为简单,只需要设置 CHANGE MASTER TO 命令中的 MASTED_DELAY 选项即可在搭建主从库延迟。
也可针对已经运行的从库设置,具体命令如下:
stop slave;
CHANGE MASTER TO MASTED_DELAY = 28800;
start slave;
延迟复制的相关信息可通过 SHOW SLAVE STATUS 查看。
延迟复制在本质上是慢点执行 SQL 线程的应用,并不影响 I/O 线程接受主库的 binlog。
需要注意的是,在执行完CHANGE MASTER TO MASTED_DELAY=28800 后,从库会清除已有的 relay log,并基于 Relay_Master_log_file 和 Exec_Master_log_Pos 的值来重新初始化 Master_log_file 和 Read_Master_log_Pos。
6. 并行复制
主从延迟的原因,对于写入 binlog 的二进制日志文件,从库上只有一个 SQL 线程进行重放,但是这些二进制日志事件在主库上是并发写入的。就好比多人挖坑一人填坑,一旦挖坑的人稍微加速,填坑的人就跟不上了,就只能看着坑越来越大,意味着 Seconds_Behind_Master 的值会越来越大。
主从延迟可不是什么好事,在读写分离的场景下,意味着业务会读到旧数据。如果延迟过大,会影响数据库的高可用切换,如果等待从库应用完差异的 binlog 才做高可用切换,无疑会影响数据库服务的可用性。如果不等待,直接切换则会导致数据丢失。
MySQL 5.6基于库的并行复制出来后,基本无人问津,因为线上环境大部分是单库多表,所以基于库级别实际用的不多
到了MySQL 5.7,才实现了真正的并行复制(slave-parallel-type=LOGICAL_CLOCK),复制效率提升很多。MySQL 5.7的并行复制,multi-threaded slave即MTS,期望最大化还原主库的并行度,实现方式是在binlog event中增加必要的信息,以便slave节点根据这些信息实现并行复制。
MySQL5.7 基于组提交的并行复制方案(了解就行了,这部分比较难)
Commit-Parent-Based Lock-Free 并行复制模式是在 MySQL 5.7 版本中引入的,它利用事务的准备阶段(Prepare phase)来识别可以并行执行的事务组。这个模式通过在二进制日志中记录事务的 commit-parent 值来实现,如果两个事务的 commit-parent 值相同,它们就可以在从库上进行并行复制。
Lock-Based Parallel Copy 模式是在 MySQL 5.7 版本中作为对 Commit-Parent-Based 模式的改进而引入的。它通过引入锁区间(locking interval)的概念来提高并行复制的效率。这个模式考虑了事务持有锁的时间范围,只有当两个事务的锁区间没有冲突时,它们才能并行执行。
要开启 MySQL 5.7 并行复制需要以下2步:
1、首先在主库设置 binlog_group_commit_sync_delay 的值大于0 。
set global binlog_group_commit_sync_delay=10;
set global binlog_group_commit_sync_no_delay_count=10;
binlog_group_commit_sync_delay 全局动态变量,单位微妙,默认0,范围:0~1000000(1秒)。 表示 binlog 提交后等待延迟多少时间再同步到磁盘,默认0 ,不延迟。当设置为 0 以上的时候,就允许多个事务的日志同时一起提交,也就是我们说的组提交。组提交是并行复制的基础,我们设置这个值的大于 0 就代表打开了组提交的功能。
binlog_group_commit_sync_no_delay_count 全局动态变量,单位个数,默认0,范围:0~1000000。 表示等待延迟提交的最大事务数,如果上面参数的时间没到,但事务数到了,则直接同步到磁盘。若 binlog_group_commit_sync_delay 没有开启,则该参数也不会开启。
2、其次要在 Slave 主机上设置如下几个参数:
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 16
slave_preserve_commit_order = ON
slave_parallel_type 设置从库并行的类型,该参数有以下两个值可选
LOGICAL_CLOCK:基于组提交的并行复制
DATABASE:基于库级别的并行复制
slave_parallel_workers :设置 worker 线程的数量
slave_preserve_commit_order :事务在从库上的提交顺序是否和主库一致。
调整好这三个参数之后,需要重启复制才会生效。
从 MySQL5.7.22 和 MySQL8.0 开始,可使用 WRITESET 方案进一步提高复制效率,需要在主库上设置以下参数
binlog_transaction_dependency_tracking = WRITESET_SESSION
transaction_write_set_extraction = XXHASH64
binlog_transaction_dependency_history_size = 25000
bing_format = ROW
7. GTID 复制
7.1. GTID Replication介绍
GTID(Global Transaction Identifier,全局事务 ID)是 MySQL5.6 引入的新特性,它会为每个事务分配一个唯一的事务 ID。
借助GTID,在发生主备切换的情况下,MySQL的其他slave可以自动在新主上找到正确的复制位置,这大大简化了复杂复制拓扑下集群的维护,也减少了人为设置复制position发生误操作的风险。另外,基于GTID的复制可以忽略已经执行过的事务,减少了数据发生不一致的风险。
7.2. GTID 的组成
事务 ID 的格式如下:
source_id:transaction_id
source_id 表示事务是在那个实例上产生的,通常用实例的 server_uuid 来表示。该值是 MySQL 第一次启动时自动并持久化到 auto.cnf 文件上(该文件在数据目录里)。我们也可以查询该命令 show global variables like '%uuid';查询到。
transaction_id 是事务的序列号。它是一个从1开始的自增计数,表示在这个主库上执行的第n个事务。一组连续的事务可以使用“-”连接的事务序号范围来表示。例如:0c8bc979-0ec8-11f0-808a-bc2411a7dcc2:1-15。
这个事务 ID 并不是无上限,在官方文档中有写道The upper limit for sequence numbers for GTIDs on a server instance is the number of non-negative values for a signed 64-bit integer ,所以事务自增 ID 的最大值为2 to the power of 63 minus 1, or 9,223,372,036,854,775,807 。
如果超过了这个值,MySQL 会发生由二进制日志错误产生的行为(binlog_error_action 指定的行为),默认为 ABORT_SERVER,暂停日志记录并关闭服务器。不过放心啦,这个值很大的,理论上不会触发到。
7.3. 开启 GTID 之后 binlog 变化
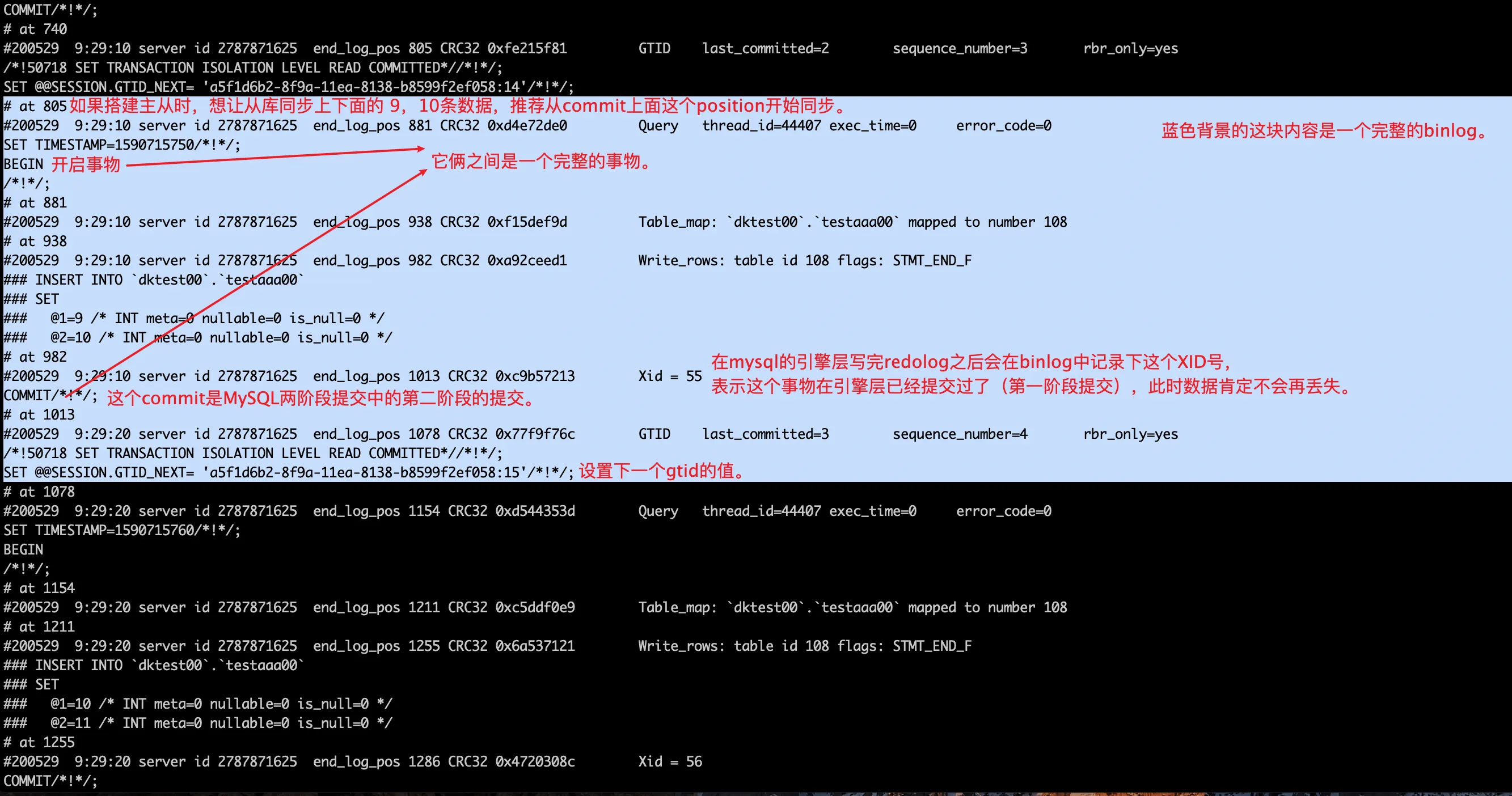
开启 GTID 必备参数
log-bin=mysql-bin
binlog_format=row
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=ON
其中参数log_slave_updates在5.7中不是强制选项,其中最重要的原因在于5.7在mysql库下引入了新的表gtid_executed。
master_info_repository 决定复制的相关信息是保存在文件中还是系统表中,file为文件,table为系统表
评论