一、TOAST是什么?
TOAST是“The Oversized-Attribute Storage Technique”(超尺寸字段存储技术)的缩写,主要用于存储一个大字段的值。
要理解TOAST,我们要先理解页(BLOCK)的概念。在PG中,页是数据在文件存储中的基本单位,其大小是固定的且只能在编译期指定,之后无法修改,默认的大小为8KB。同时,PG不允许一行数据跨页存储。那么对于超长的行数据,PG就会启动TOAST,将大的字段压缩或切片成多个物理行存到另一张系统表中(TOAST表),这种存储方式叫行外存储。
二、四种TOAST的策略
PLAIN:避免压缩和行外存储。只有那些不需要TOAST策略就能存放的数据类型允许选择(例如int类型),而对于text这类要求存储长度超过页大小的类型,是不允许采用此策略的
EXTENDED:允许压缩和行外存储。一般会先压缩,如果还是太大,就会行外存储
EXTERNA:允许行外存储,但不许压缩。类似字符串这种会对数据的一部分进行操作的字段,采用此策略可能获得更高的性能,因为不需要读取出整行数据再解压。
MAIN:允许压缩,但不许行外存储。不过实际上,为了保证过大数据的存储,行外存储在其它方式(例如压缩)都无法满足需求的情况下,作为最后手段还是会被启动。因此理解为:尽量不使用行外存储更贴切。
现在我们通过实际操作来研究TOAST的细节:
postgres=# create table blog(id int,title text,context text);
CREATE TABLE
postgres=# \d+ blog;
Table "public.blog"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
---------+---------+-----------+----------+---------+----------+-------------+--------------+-------------
id | integer | | | | plain | | |
title | text | | | | extended | | |
context | text | | | | extended | | |
Access method: heapinterger默认TOAST策略为plain,而text为extended。PG资料告诉我们,如果表中有字段需要TOAST,那么系统会自动创建一张TOAST表负责行外存储,那么这张表在哪里?
select relname,relfilenode,reltoastrelid from pg_class where relname='blog';
Name |Value|
-------------+-----+
relname |blog |
relfilenode |57396|
reltoastrelid|57399|通过上诉语句,我们查到blog表的oid为57396,其对应TOAST表的oid为16444,那么其对应TOAST表名则为:pg_toast.pg_toast_57396(注意这里是blog表的oid),我们看下其定义:
postgres=# \d+ pg_toast.pg_toast_57396;
TOAST table "pg_toast.pg_toast_57396"
Column | Type | Storage
------------+---------+---------
chunk_id | oid | plain
chunk_seq | integer | plain
chunk_data | bytea | plain
Owning table: "public.blog"
Indexes:
"pg_toast_57396_index" PRIMARY KEY, btree (chunk_id, chunk_seq)
Access method: heapTOAST表有3个字段:
chunk_id:用来表示特定TOAST值的OID,可以理解为具有同样chunk_id值的所有行组成原表(这里的blog)的TOAST字段的一行数据
chunk_seq:用来表示该行数据在整个数据中的位置
chunk_data:实际存储的数据。 现在我们来实际验证下:
insert into blog values(1,'title','abcdeabcde');
select * from pg_toast.pg_toast_57396;因为对于单个字段,如果其大小超过 TOAST_TUPLE_TARGET(默认也是 2KB),即使整行未超过阈值,该字段也可能被 TOAST 处理。此时因为 content 只有十个字符,所以没有被压缩也没有行外存储。那我们插入一条 2KB 的数据试试看。
INSERT INTO blog(id, title, context) VALUES (1, '大文章', repeat('这是一个会被TOAST存储的文本内容。', 50));此时这条数据大小是超过 2KB 了,但是查询pg_toast_57396 却没有数据,那我们来实际看看这条数据的大小。
SELECT id,pg_column_size(blog.*) AS entire_row_bytes FROM blog;
pg_column_size|
--------------+
129|咦,才 129 字节,怎么可能,上文我们有说过,EXTENDED允许压缩和行外存储。原来如此,那我们先禁用压缩,然后插入数据看看。
ALTER TABLE blog ALTER COLUMN context SET STORAGE EXTERNAL;
INSERT INTO blog(id, title, context) VALUES (1, '大文章', repeat('这是一个会被TOAST存储的文本内容。', 50));
select * from pg_toast.pg_toast_57396;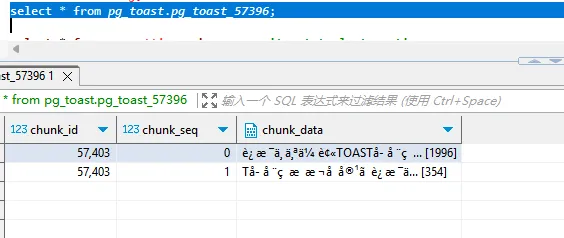
此时我们再次查询,TOAST表中产生了新的2条chunk_id为 57403 的行,且2行数据的chunk_data的长度之和正好等于 2350。通过以上操作得出以下结论:
如果策略允许压缩,则TOAST优先选择压缩
不管是否压缩,一旦数据超过2KB左右,就会启用行外存储
修改TOAST策略,不会影响现有数据的存储方式
评论