流复制介绍
什么是流复制?
如果有人问你PostgreSQL的流复制究竟是什么?你大概会说通过wal日志来进行数据同步之类的,的确如此,流复制大概就是这么回事。
但是准确的来说:PostgreSQL通过wal日志来传送的方式有两种:基于文件的日志传送和流复制。
不同于基于文件的日志传送,流复制的关键在于“流”,所谓流,就是没有界限的一串数据,类似于河里的水流,是连成一片的。因此流复制允许一台后备服务器比使用基于文件的日志传送更能保持为最新的状态。
比如我们有一个大文件要从本地主机发送到远程主机,如果是按照“流”接收到的话,我们可以一边接收,一边将文本流存入文件系统。这样,等到“流”接收完了,硬盘写入操作也已经完成。
流复制发展历史
像我们上面说的,pg在流复制出现之前,使用的就是基于文件的日志传送:当主库写完一个 WAL 日志后,才把 WAL 日志拷贝到从库上,本质上是通过 cp 命令实现远程备份,这种备份通常会落后主库一个 WAL 日志文件。
而流复制出现是从2010年推出的pg9.0开始的,其历史大致为:
起源:pg9.0开始支持流式物理复制,用户可以通过流式复制,构建只读备库(主备物理复制,块级别一致)。流式物理复制可以做到极低的延迟(通常在1毫秒以内)。
同步流复制:pg9.1开始支持同步复制,但是当时只支持一个同步流复制备节点(例如配置了3个备,只有一个是同步模式的,其他都是异步模式)。同步流复制的出现,保证了数据的零丢失。
级联流复制:pg9.2支持级联流复制。即备库还可以再连备库。
流式虚拟备库:pg9.2还支持虚拟备库,即就是只有WAL,没有数据文件的备库。
逻辑复制:pg9.4开始可以实现逻辑复制,逻辑复制可以做到对主库的部分复制,例如表级复制,而不是整个集群的块级一致复制。
增加多种同步级别:pg9.6版本开始可以通过synchronous_commit[local, remote_write, remote_apply, on, off]参数,来配置事务的同步级别。
synchronous_commit参数详解
1. ON(默认值)
行为:
事务提交时,必须等待 WAL 记录写入本地磁盘
如果配置了同步备库(synchronous_standby_names),还必须等待至少一个同步备库将 WAL 写入磁盘
特点:
提供最高级别的数据安全性
主库和同步备库都不会丢失已提交的事务
性能影响最大(延迟最高)
适用场景:
金融交易等对数据一致性要求极高的场景
2. remote_write
行为:
事务提交时,必须等待 WAL 记录写入本地磁盘
对于同步备库,只需等待备库接收到 WAL 数据并写入操作系统缓存(不需要刷盘)
特点:
比 on 性能更好
备库崩溃可能导致少量未刷盘的数据丢失
主库数据仍然安全
适用场景:
可以容忍备库少量数据丢失的高性能需求场景
3. remote_apply
行为:
事务提交时,必须等待 WAL 记录写入本地磁盘
对于同步备库,必须等待备库不仅接收而且应用了 WAL 记录
特点:
最严格的同步级别
主备库数据完全一致
性能影响最大
适用场景:
需要备库立即反映主库变化的场景(如故障切换后零数据丢失)
4. local
行为:
事务提交时,只需等待 WAL 记录写入本地磁盘
完全不管备库的状态
特点:
主库数据安全
备库可能落后或丢失数据
性能较好
适用场景:
允许备库异步复制的场景
5. off
行为:
事务提交时,WAL 记录可能还在内存中未写入磁盘
完全不管备库的状态
特点:
最高性能
主库崩溃可能导致数据丢失
备库数据更不可靠
适用场景:
非关键数据(如缓存、临时表等可以重建的数据)
流复制概述
流复制其原理为:备库不断的从主库同步相应的数据,并在备库apply每个WAL record,这里的流复制每次传输单位是WAL日志的record。
PostgreSQL物理流复制按照同步方式分为两类:
配置项为synchronous_commit,OFF 表示异步,ON 表示同步,remote_write 表示半同步复制。
同步复制
要等待Standby 节点接收并写入 WAL 日志后Primary 节点才会向客户端返回成功,这样的好处是强一致性,Primary 和 Standby 的 WAL 日志完全同步,缺点嘛,也很明显,要是Standby 迟迟不返回结果,那么 Paimary 只能等待,不过也不会一直等待下去,参数wal_sender_timeout 表示超时时间,默认是 60s,超过这个时间,主库会终止 wal sender 进程。该参数是网络层面的,即使wal_sender_timeout 超时之后,还是会继续堵塞,因为该参数是物理层面的断开,而事务是逻辑层的。
如果在多个从节点的情况下,主节点都要等待多个从节点返回 ACK 确定,但一故障都会导致主节点堵塞。我们可以配置 synchronous_standby_names 该参数来确定必须要等到那个从节点返回 ACK,主库才不会堵塞。
如果该参数为空,即使配置了同步级别,实际上相当于异步。
SELECT application_name FROM pg_stat_replication;
ALTER SYSTEM SET synchronous_standby_names = 'standby1'; -- 指定一个同步备库
#或(PG 14+ 支持 ANY 语法,推荐):
ALTER SYSTEM SET synchronous_standby_names = 'ANY 1(standby1, standby2)'; -- 任意一个备库确认即可
#重载配置(无需重启)
SELECT pg_reload_conf(); -- 使配置生效同步选择 "宁可阻塞也不丢数据",确保每个已提交事务绝对安全。
异步复制
则是Primary 在执行完更新操作后立即向应用程序返回响应,然后 Primary 再向 Standby 复制数据。因为数据并非实时同步到 Standby,而 Primary 在 Standby 有延迟的情况下发生故障后发生切换则有较小概率会引起数据不一致。
异步不管从库的死活,不管从库有没有收到,只管发送就是了
半同步复制
其实半同步的执行流程跟同步是差不多,但是逻辑层面上的处理不一样,在多个从节点的情况下,主节点只需要一个从节点返回 ACK 即可。
物理流复制具有以下特点:
1、延迟极低,不怕大事务
2、支持断点续传
3、支持多副本
4、配置简单
5、备库与主库物理完全一致,并支持只读
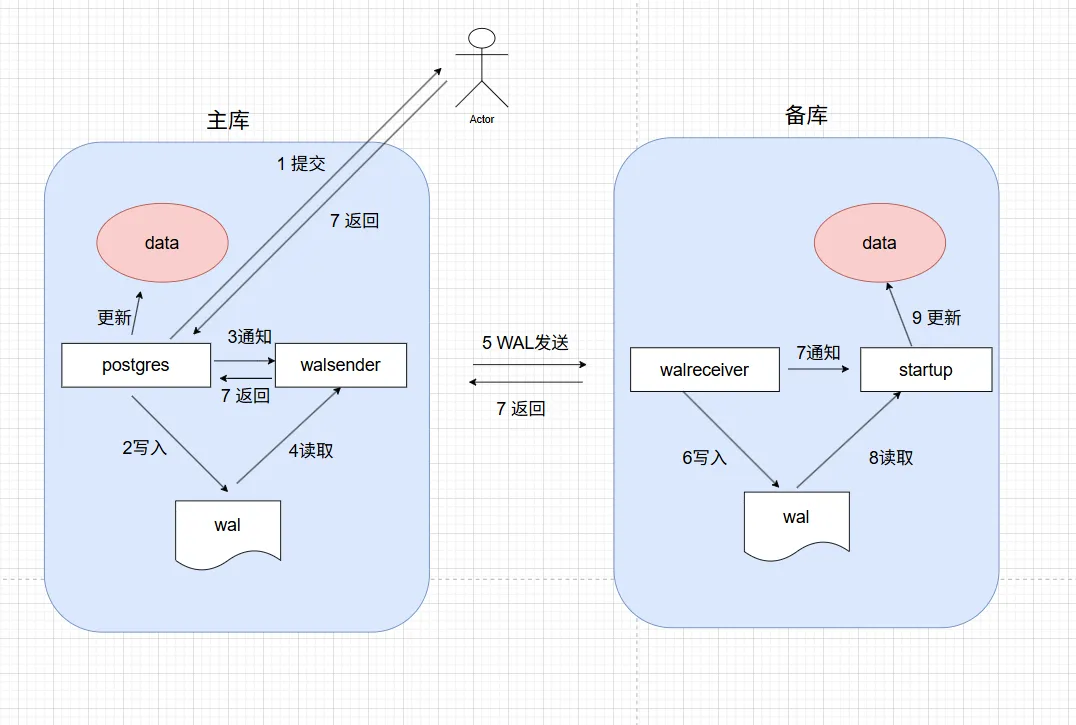
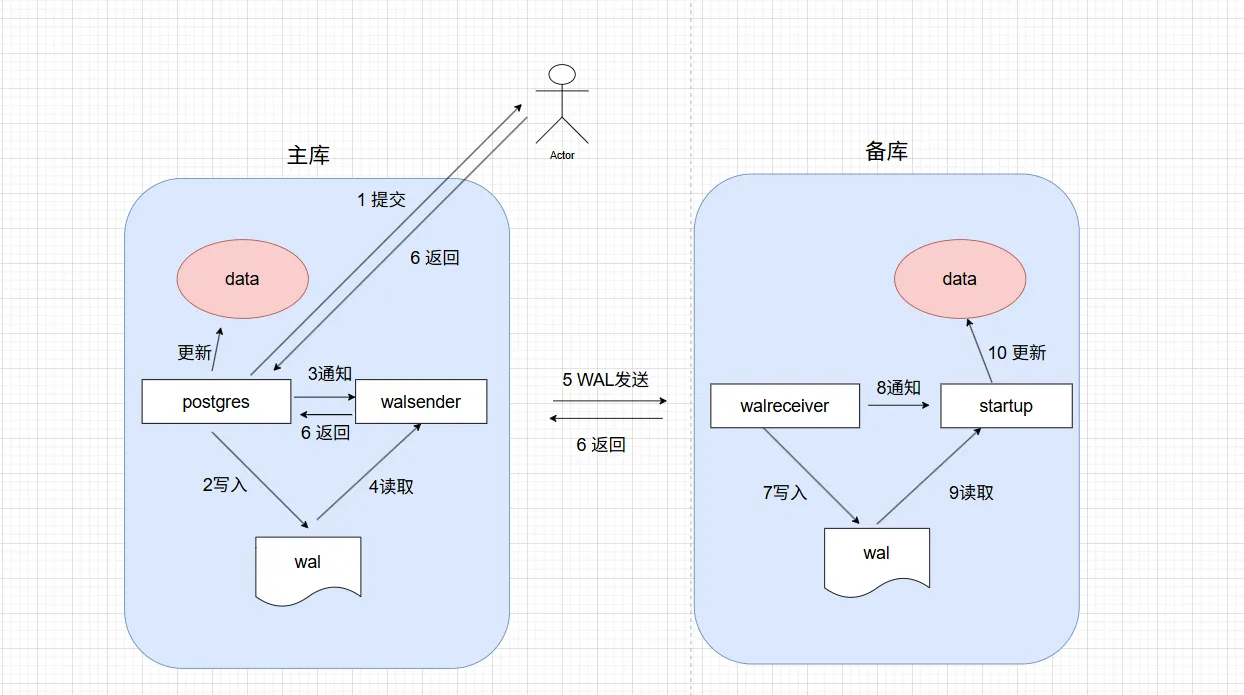
工作流程
PostgreSQL 流复制的核心部分由walreceiver,walsender 和 startup 三个进程组成。有三个进程协同工作,
walsender 在主节点发送 wal 数据到备节点。然后备节点启用一个 walreceiver 和 一个 startup 进程接受和重放数据。
walsender 主要负责读取 WAL 日志并通过 TCP 流式传输到从库。
walreceiver 接收 WAL 日志并写入到本地 PG_WAL 目录。
startup 负责解析 WAL 日志并应用到数据文件,实现物理页恢复。
通信协议
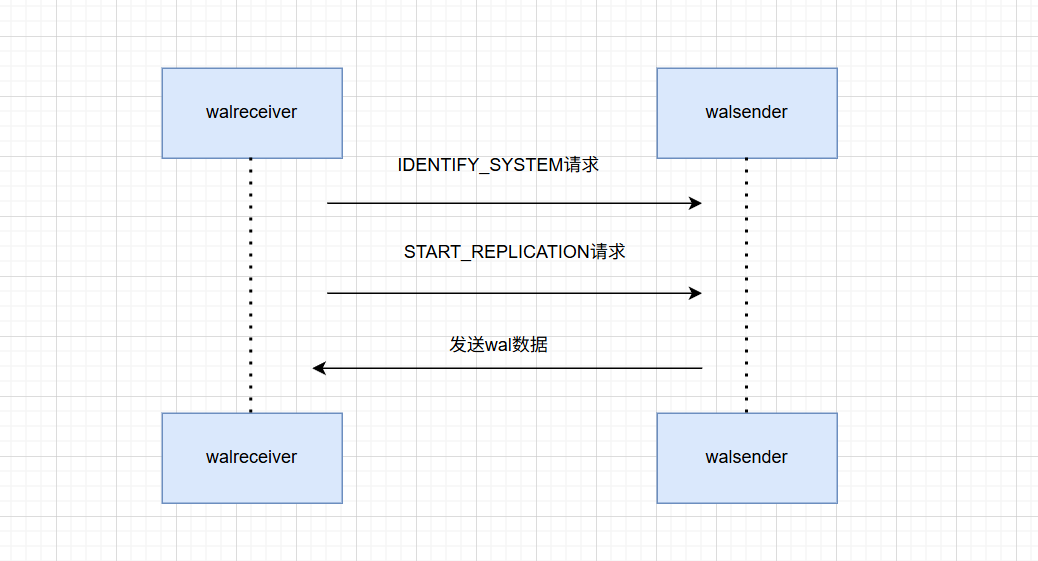
首先从库会发送IDENTIFY_SYSTEM请求,用来确认主库的身份。每个 postgresql 数据库在第一次初始化时,都会分配一个唯一的systemid。当配置主从复制时,从库需要将主库的数据备份过来,这时候也会拷贝systemid,所以从库和主库的systemid是一样的。主库处理IDENTIFY_SYSTEM请求时,会返回自身的systemid。从库通过匹配它,可以判断出来主库的有效性。比如当用户在配置时错写了主库的地址,就可以检查出来。
从库在确认主库的身份后,就会发送START_REPLICATION请求,其中包含了从库想要获取的 wal 数据位置。主库收到请求后,会去检查该 wal 数据是否存在。如果不存在,主库会返回错误信息。从库收到错误信息后,会直接退出。如果发生了这种情况,那么我们则需要重新备份了,重新配置主从复制了。
在确认 wal 数据存在后,主库会传输数据给从库。
心跳
从库会定期向主库汇报自身的同步进度,比如已经刷新wal数据的位置,已经应用wal数据的位置等,这样主库就可以了解到每个从库的情况。
当主库超过指定时间间隔,没有收到来自从库的消息,会发送Keepalive消息,强制要求从库汇报自身进度。
实现原理
上面讲述了主库和从库之间的通信协议,这里继续讲解他们各自内部的实现。
从库
进程
从库的同步涉及到 wal 数据的获取和执行,分别由 walreciever 和 recovery 两个进程负责。walreciever 进程负责从主库中获取wal数据,当接收到新的 数据后,会通过 recovery 进程。recovery 进程负责读取并且执行接收的wal 数据。recovery 进程一直会读取新的 wal 数据并且应用,如果没有新的数据,它会阻塞等待 walreceiver 的唤醒。
状态
walreceiver 进程的状态表示从库的同步状态。它在启动的时候,状态为WALRCV_STARTING。启动完后,状态变为WALRCV_STREAMING。
walreceiver 进程在接收完指定 timeline 的数据后,会变为WALRCV_WAITING状态。等待后续指令。
recovery 进程在执行完这个 timeline 的数据后,会将 walceiver 的状态设置为WALRCV_RESTARTING。
walreceiver 向主库发起请求,获取下一个 timeline 的数据,状态会变为WALRCV_STREAMING。
walreceiver 会一直请求到最近的 timeline,直到和主库保持一致。
walreceiver 的状态会一直保持为WALRCV_RESTARTING,直到数据库关闭,变为WALRCV_STOPPING。
汇报
从库在空闲时间,会每隔100ms,检查一次。如果超过 wal_receiver_timeout / 2的时间,没有收到主库的信息,那么它会强制发送自身的信息到主库,包含自身的wal数据写入位置,刷新位置,应用位置。
如果没有超过,则试图发送自身的信息到主库。这里还需要考虑从库汇报自身信息的最低时间间隔,由wal_receiver_status_interval表示,如果小于时间间隔,那么则不会发送。
主库
进程
主库在接收到了从库的请求后,会创建 walsender 进程负责处理,walsender 会将 wal 数据发送给从库。当从库已经追赶上了主库,那么 walsender 会等待新的 wal 数据产生。
如果主库处理了来自客户的写请求,产生了新的wal 数据,会唤醒 walsender 进程。
状态
walsender 的初始状态为 WALSNDSTATE_CATCHUP,表示从库正在追赶主库。
当从库在追上主库后,状态会变为WALSNDSTATE_STREAMING,然后会一直维持这个状态。
心跳
wal_sender_timeout表示从库的超时时间,如果从库超过这段时间,一直没有信息,那么主库就会认为它出现了问题,会断开该连接。
如果超过了wal_sender_timeout / 2的时间,从库都没反应,那么主库会发送keepalive消息给从库,从库必须立即回应。
监控指标
主库监控
在主库执行下列 sql,可以获得从库的相关信息。不过有些信息都是由从库汇报上来的,比如flush_lsn,replay_lsn,会有一些延迟。
postgres=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 22219
usesysid | 25411
usename | repl
application_name | walreceiver
client_addr | 192.168.1.2
client_hostname |
client_port | 35442
backend_start | 2020-05-06 14:40:58.271771+08
backend_xmin |
state | streaming
sent_lsn | 0/70209B0
write_lsn | 0/70209B0
flush_lsn | 0/70209B0
replay_lsn | 0/70209B0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2020-05-06 14:41:08.308271+08从库监控
postgres=# select * from pg_stat_wal_receiver;
-[ RECORD 1 ]---------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 852
status | streaming
receive_start_lsn | 0/7000000
receive_start_tli | 1
received_lsn | 0/7000000
received_tli | 1
last_msg_send_time | 2020-05-06 14:53:59.640178+08
last_msg_receipt_time | 2020-05-06 14:53:59.640012+08
latest_end_lsn | 0/70209B0
latest_end_time | 2020-05-06 14:40:58.293124+08
slot_name |
sender_host | 192.168.1.1
sender_port | 15432
conninfo | ...关于上面主控监控中,从库的关于 wal 的恢复信息获取会存在延迟。不过我们可以直接在从库上实时获取
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn | pg_last_xact_replay_timestamp
-------------------------+------------------------+-------------------------------
0/70209B0 | 0/70209B0 | 2020-04-30 17:15:24.425998+08
(1 row)
评论