redo 介绍
重做日志主要记录对数据所做的所有更改,包括未提交和已提交的更改。
Oracle通过Redo来保证数据库的事务可以被重演,从而使得在故障之后,数据可以被恢复。在数据库中,Redo的功能主要通过3个组件来实现:Redo Log Buffer、LGWR后台进程和Redo Log File(在归档模式下,Redo Log File最终会经由ARCn进程写出为归档日志文件)。
在数据发生commit时,将更改的SQL脚本写入在线重做日志(ONLINE REDO LOG)。主要用于数据库的增量备份和增量恢复。体系图如下所示:
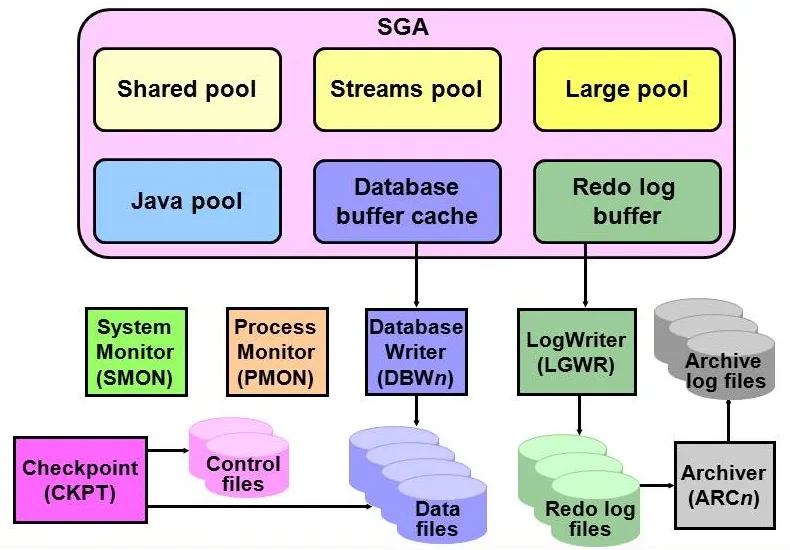
Redo 核心组件
Redo Log Buffer
位于SGA之中,是一块循环使用的内存区域,其保存数据库变更的相关信息。这些信息以重做条目(Redo Entries)形式存储(Redo Entries也经常称为Redo Records)。
Redo Entries包含重构、重做数据库变更的重要信息,这些变更包括INSERT、UPDATE、DELETE、CREATE、ALTER或者DROP等。
Redo Entries的内容被Oracle数据库进程从用户的内存空间(PGA)复制到SGA中的Redo Log Buffer之中。Redo Entries在内存中占用连续的顺序空间,由于Redo Log Buffer是循环使用的,Oracle通过一个后台进程LGWR不断把Redo Log Buffer的内容写出到Redo Log File中,Redo Log File同样是循环使用的。
Redo Log Buffer:如果数据需要写到在线重做日志中,则在写至磁盘之前要在Redo Buffer中临时缓存这些数据。由于内存到内存的传输比内存到磁盘的传输快得多,因此使用重做日志Buffer可以加快数据库的操作。数据在重做缓冲区的停留时间不会太长。
LGWR
LGWR是Log Writer的缩写,日志写进程。主要负责将日志缓冲内容写到磁盘的在线重做日志文件或组中。
DBWn将dirty块写到磁盘之前,所有与buffer修改相关的redo log都需要由LGWR写入磁盘的在线重做日志文件(组),如果未写完,那么DBWn会等待LGWR,也会产生一些相应的等待事件(例如:log file prarllel write。
总之,这样做的目的就是为了当crash时,可以有恢复之前操作的可能,也是Oracle在保持交易完整性方面的一个机制。
相关知识点:
1、LGWR写日志是顺序写,这就解释了一个Orace Server只能有一个LGWR进程,不能像DBWR那样可以有多个,否则就无法保证顺序写的机制,而且可能会产生锁的问题。
2、用户进程每次修改内存数据块时,都会在日志缓冲区(redo buffer)中构造一个相应的重做条目(redo entry),它记录了被修改数据块修改之前和之后的值。
3、LGWR将redo entry写入联机日志文件的情况可以概括为两种:后台写和同步写,或者说异步写和同步写。
二、LGWR进程刷磁盘机制
1、当用户进程提交一事务时写入一个提交记录
2、每3秒将日志缓冲区写入日志文件
3、当日志缓冲区满1/3时,将日志缓冲刷出
4、当DBWR将修改缓冲区写入磁盘前,将日志缓冲区刷出
日志缓冲区是一个循环缓冲区。当LGWR将日志缓冲区的日志写入日志文件后,服务器进程即可以将新的日志项写入到该日志缓冲区。LGWR写入速度很快,以确保日志缓冲区总有空间可以写入新的日志项。
ARCn
归档进程,ARCn的任务就是,当LGWR将在线日志文件填满时,就将其复制到另外一个位置。此后这些归档的重做日志文件可以用于完成介质恢复。
Redo Log Files
重做日志文件,以组出现。可以查询v$logfile找到对应的日志文件。
Redo 工作流程
每个Oracle数据库都至少有两个Online重做日志组,每个组中至少有一个重做日志文件,这些在线重做日志组以循环方式使用。(用户可以通过视图操作添加/修改/删除日志组和日志文件来自定义在线重做日志),每组内的日志文件的内容完全相同,且保存在不同的位置,用于磁盘日志镜像,以做多次备份提高安全性。
默认情况这n组通常只有一组处于活动状态,不断地同步写入已操作的脚本,当日志文件写满时(达到指定的空间配额),如果当前数据库处于归档模式,则将在线日志归档到硬盘,成为归档日志;若当前数据库处于非归档模式,则不进行归档操作,而当前在线日志的内容会被下一次重新写入覆盖而无法保存。
因此,通常对于生产环境的数据库在运行时,是要处于归档模式下的,以保存数据更新的日志。当前归档日志组写满后,Oracle会切换到下一日志组,继续写入,就这样循环切换;当处于归档模式下,切换至原已写满的日志组,若该日志组归档完毕则覆盖写入,若没有则只能使用日志缓冲区,等待归档完毕之后才能覆盖写入。
所以在生产环境中,要求存放 Redo 文件和归档文件的 IO 性能不能相差太多。
当然,处于非归档模式下是直接覆盖写入的。归档重做日志文件实际上就是已填满的“旧”的在线重做日志文件的副本。系统将日志文件填满时,ARCH进程会在另一个位置建立重做日志文件的一个副本,也可以在本地或者远程位置上建立多个另外的副本。
如果由于磁盘损坏或者其他物理故障而导致失败,就会用这些归档重做日志文件来执行介质恢复。默认情况下,一个数据库默认为非归档模式,如果是非归档模式的话,也就说明我们没有办法通过日志来对数据库做一个恢复。
查看REDO LOG状态信息(V$LOG)
查询V$LOG动态性能视图后的结果,这里我们主要关注红色字体部分,这里表示REDO LOG组状态。

可以看到我们这里已经有两种状态为INACTIVE和CURRENT
那么我们把REDO LOG组所有的状态都列出来。并给出相应解释:
UNUSED - 从未对联机重做日志组进行写入,这种状态的日志文件要么是刚增加的,要么是当日志不是current redo log时RESETLOGS操作后的状态
CURRENT - 当前的联机重做日志组,这意味着该联机重做日志组是活动的。
ACTIVE - 联机重做日志组是活动的,但是并非当前联机重做日志组,实例崩溃恢复需要该状态的日志,它可能用于块恢复,它可能已经归档也可能未归档。
CLEARING - 在ALTER DATABASE CLEAR LOGFILE 命令后正在将该日志重建为一个空日志,日志清除后其状态更改为UNUSED。
CLEARING_CURRENT - 正在清除当前日志文件中的已关闭线程,如果切换时发生某些故障,如写入新日志标题时的I/O错误,则该日志可以停留在该状态。
INACTIVE - 实例恢复不再需要联机重做日志组,它可能已经归档也可能未归档。
查看REDO LOG状态信息(V$LOGFILE)
查询V$LOGFILE动态性能视图后的结果,这里我们主要关注红色字体部分,这里表示REDO LOG文件状态。
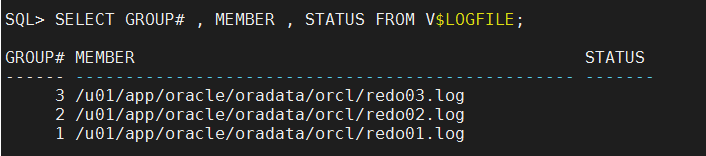
可以看到我们这里STATUS(状态)列下并无数据,但实际上现在这个列中的值为NULL,那么我们把REDO LOG文件所有的状态都列出来。并给出相应解释:
INVALID – 该文件不可访问
STALE - 该文件内容不完全,例如正在添加一个日志文件成员
DELETED - 该文件已不再使用
NULL – 该文件正在使用中
REDO日志切换命令
REDO组可以用两种方法去切换:
正常切换: (推荐使用)
alter system switch logfile;用发生检查点的方式去切换:(切换相关状态)
alter system checkpoint;归档模式 vs 非归档模式
1.非归档模式
不适用与生产数据库
创建数据库时,缺省的日志管理模式为非归档模式
当日志切换,检查点产生后,联机重做日志文件即可被重新使用
联机日志被覆盖后,介质恢复仅仅支持到最近的完整备份
不支持联机备份表空间,一个表空间损坏将导致整个数据库不可用,需要删除掉损坏的表空间或从备份恢复
对于操作系统级别的数据库备份需要将数据库一致性关闭
应当备份所有的数据文件、控制文件(单个)、参数文件、密码文件、联机日志文件(可选)
2.归档模式
能够对联机日志文件进行归档,生产数据库强烈建议归档
在日志切换时,下一个即将被写入日志组必须归档完成之后,日志组才可以使用
归档日志的Log sequence number信息会记录到控制文件之中
必须有足够的磁盘空间用于存放归档日志
备份与恢复
支持热备份,且当某个非系统表空间损坏,数据库仍然处于可用状态,且支持在线恢复
使用归档日志能够实现联机或脱机时间点恢复(即可以恢复到指定的时间点、指定的归档日志或指定的SCN)
生产常用的 redo 监控查询脚本
#查看日志组和日志文件信息
select * from v$logfile;
select * from v$log;
#果数据库启用了归档模式,可以通过以下查询查看归档日志:
SELECT * FROM v$archived_log;
#通过查看在线重做日志 redo log 每小时的切换次数,可以知道数据库的繁忙程度
SELECT TRUNC(first_time) "Date",
TO_CHAR(first_time, 'Dy') "Day",
COUNT(1) "Total",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '00', 1, 0)) "h0",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '01', 1, 0)) "h1",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '02', 1, 0)) "h2",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '03', 1, 0)) "h3",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '04', 1, 0)) "h4",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '05', 1, 0)) "h5",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '06', 1, 0)) "h6",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '07', 1, 0)) "h7",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '08', 1, 0)) "h8",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '09', 1, 0)) "h9",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '10', 1, 0)) "h10",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '11', 1, 0)) "h11",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '12', 1, 0)) "h12",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '13', 1, 0)) "h13",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '14', 1, 0)) "h14",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '15', 1, 0)) "h15",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '16', 1, 0)) "h16",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '17', 1, 0)) "h17",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '18', 1, 0)) "h18",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '19', 1, 0)) "h19",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '20', 1, 0)) "h20",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '21', 1, 0)) "h21",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '22', 1, 0)) "h22",
SUM(DECODE(TO_CHAR(first_time, 'hh24'), '23', 1, 0)) "h23",
ROUND(COUNT(1) / 24, 2) "Avg"
FROM v$log_history
GROUP BY TRUNC(first_time), TO_CHAR(first_time, 'Dy')
ORDER BY 1;小实验
redolog
默认情况下 redo 有三组,每组有一个 logfile,我们可以新增多个 redofile。
#查看日志文件的位置
select member from v$logfile;
#新增日志文件
alter database add logfile member 'xxxxxxxxxxxxx/redo01.rdo' to group 1;
#删除组内的日志文件,至少要有一个日志文件。
#注意的是,删除只是更新控制文件,并不涉及物理操作,该文件还在磁盘上。
#该组若处于CURRENT状态,则不允许删除。
alter database drop logfile member 'xxxxxxxxxxxxx/redo01.rdo';redo 组
#新增redo组
ALTER DATABASE ADD LOGFILE GROUP 4 (filelog位置) SIZE 300M;
#删除redo组
ALTER DATABASE DROP LOGFILE GROUP 4;
评论