基数(CARDINALITY)
某个列唯一键的数量叫作基数。比如性别列,该列只有男女之分,故这一列基数为2。
主键列的基数等于表的总行数。基数的高低影响列的数据分布。
当查询结果是返回表中5%以内的数据时,应该走索引;当查询结果返回的是超过表中5%的数据时,应该走全表扫描。
这就意味着当某个列基数很低,该列数据分布就会很不均匀,由于该列分布不均匀,会导致SQL查询可能走索引,也可能走全表扫描。我们可以用以下语句来查看列的分布情况。
select 列,count(*) from 表 group by 列 order by 2 desc;选择性(SELECTIVITY)
基数与总行数的比值再乘以100%就是某个列的选择性。下面的脚本用于查询表中每个列的基数与选择性。当一个列的选择性大于20%时,说明该列的数据分布就比较均衡了。
select a.column_name,b.NUM_ROWS,a.num_distinct CARDINALITY,round(a.num_distinct/b.NUM_ROWS * 100,2) SELECTIVITY,a.HISTOGRAM,a.num_buckets
from dba_tab_col_statistics a, dba_tables b where
a.owner=b.OWNER and a.table_name=b.TABLE_NAME and a.owner='C##ZXC' and a.table_name='TEST'Q:什么列需要建立索引?
A:当一个列出现在where条件中,该列没有创建索引并且选择性大于20%,那么该列就必须建立索引,从而提升SQL查询效率。
直方图(HISTOGRAM)
前面说过某个列基数很低,该列数据分布就会很不均匀,由于该列分布不均匀,会导致SQL查询可能走索引,也可能走全表扫描,这个时候很容易走错执行计划。
如果没有对基数低的列收集直方图统计信息,基于成本的优化器(CBO)会认为该列数据分布是均衡的。
下面我们来做个实验看看
--不进行直方图收集
BEGIN
DBMS_STATS.gather_table_stats(
ownname => 'C##ZXC',
tabname => 'TEST',
estimate_percent => 100,
method_opt =>'for all columns size 1',
no_invalidate => FALSE,
degree => 1,
cascade => TRUE
);
END;
--HISTOGRAM表示没有进行直方图收集
select a.column_name,b.NUM_ROWS,a.num_distinct CARDINALITY,round(a.num_distinct/b.NUM_ROWS * 100,2) SELECTIVITY,a.HISTOGRAM,a.num_buckets
from dba_tab_col_statistics a, dba_tables b where
a.owner=b.OWNER and a.table_name=b.TABLE_NAME and a.owner='C##ZXC' and a.table_name='TEST'在没有进行直方图收集的情况下进行查询,该条件下返回了391条数据,但执行计划显示的是2816条数据。
当我把C##ZXC换成SYS,执行计划返回的也是2816条数据。这显然就不对了嘛,那么执行计划为什么会返回这个数呢?
因为该列的基数很低,只有26,整张表的总行数为73221,前面强调过,当列没有进行直方图收集时,CBO会认为该列数据是均衡的,所以73221/26 约等于2816,不管owner等于任何值,CBO故算的Rows永远都等于2816。
select * from test where owner='C##ZXC';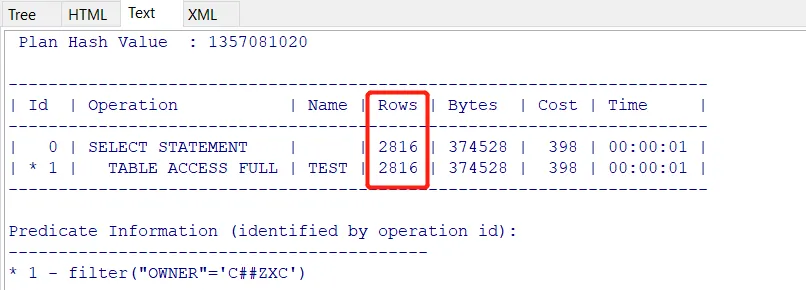
我们进行直方图收集之后再次进行查询,发现执行计划返回正确的值了。实际上收集直方图做的事情很简单,相当于运行select count(1),owner from test group by owner这条语句。
--进行直方图收集
BEGIN
DBMS_STATS.gather_table_stats(
ownname => 'C##ZXC',
tabname => 'TEST',
estimate_percent => 100,
method_opt =>'for all columns size skewonly',
no_invalidate => FALSE,
degree => 1,
cascade => TRUE
);
END;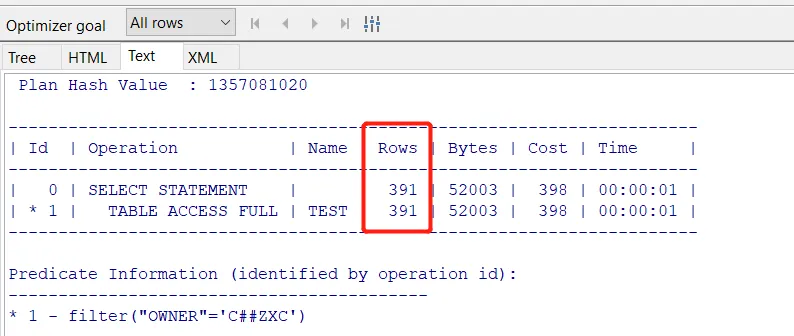
回表(TABLE ACCESS BY INDEX ROWID)
当对一个列建索引之后,索引会包含该列的键值以及键值对应行所在的rowid。
通过索引中记录的rowid访问表中的数据就叫回表。回表一般是单块读,回表次数太多会严重影响SQL性能,如果回表次数太多,就不应该走索引扫描,应该直接走全表扫描。
索引返回多少行数据,回表就要回多少次(返回表中5%以内的数据走索引,超过走全表扫描,根本原因是回表)。
Q:什么样的SQL需要回表?
A:select from table;这样的SQl就必须回表,所以我们禁止使用select 。
Q:什么样的SQL不需要回表?
A:select count(1) from table;这样的SQL不需要回表;以及当查询的列也包含在索引中。
集群因子(CLUSTERING FACTOR)
集群因子用于判断索引回表需要消耗的物理I/O次数。
select t.OWNER,t.INDEX_NAME,t.CLUSTERING_FACTOR from dba_indexes t
where t.OWNER='C##ZXC' and index_name='IDX_ID';集群因子的算法是通过判断键值对应行所在的ROWID是否在同一个数据块,如果在同个数据块,CLUSTERING_FACTOR+0,如果不在同个数据块,那么CLUSTERING_FACTOR+1。
根据算法我们知道集群因子介于表的块数和表行数之间。
如果集群因子跟块数接近,说明表的数据基本上有序的,而已其顺序基本与索引顺序一样。
这样在进行索引范围或者索引全扫描的时候,回表只需要读取少量的数据块就能完成。
如果集群因子跟表记录数接近,说明表的数据与索引顺序差异很大,在进行索引范围扫描或者索引全扫描的时候,回表会读取更多的数据块。
根据集群因子算法人工计算集群因子的SQL脚本
select sum(case
when block#1 = block#2 and file#1 = file#2 then
0
else
1
end) CLUSTERING_FACTOR
from (select dbms_rowid.rowid_relative_fno(rowid) file#1,
lead(dbms_rowid.rowid_relative_fno(rowid), 1, null) over(order by object_id) file#2,
dbms_rowid.rowid_block_number(rowid) block#1,
lead(dbms_rowid.rowid_block_number(rowid), 1, null) over(order by object_id) block#2
from test
where object_id is not null);集群因子影响的是索引回表的物理I/O次数。
我们假如buffer cache中没有缓存表的数据块,当查询返回1000行数据时,如果1000行数据在同个数据块中,那么回表需要消耗1个物理I/O,如果都在不同的数据块中,则消耗1000个物理I/O。
评论